Ancova (Stan)
This tutorial will focus on the use of Bayesian estimation to fit simple linear regression models. BUGS (Bayesian inference Using Gibbs Sampling) is an algorithm and supporting language (resembling R) dedicated to performing the Gibbs sampling implementation of Markov Chain Monte Carlo (MCMC) method. Dialects of the BUGS language are implemented within three main projects:
OpenBUGS - written in component pascal.
JAGS - (Just Another Gibbs Sampler) - written in
C++.Stan - a dedicated Bayesian modelling framework written in
C++and implementing Hamiltonian MCMC samplers.
Whilst the above programs can be used stand-alone, they do offer the rich data pre-processing and graphical capabilities of R, and thus, they are best accessed from within R itself. As such there are multiple packages dedicated to interfacing with the various software implementations:
R2OpenBUGS - interfaces with
OpenBUGSR2jags - interfaces with
JAGSrstan - interfaces with
Stan
This tutorial will demonstrate how to fit models in Stan (Gelman, Lee, and Guo (2015)) using the package rstan (Stan Development Team (2018)) as interface, which also requires to load some other packages.
Overview
Introduction
Previous tutorials have concentrated on designs for either continuous (Regression) or categorical (ANOVA) predictor variables. Analysis of covariance (ANCOVA) models are essentially ANOVA models that incorporate one or more continuous and categorical variables (covariates). Although the relationship between a response variable and a covariate may itself be of substantial clinical interest, typically covariate(s) are incorporated to reduce the amount of unexplained variability in the model and thereby increase the power of any treatment effects.
In ANCOVA, a reduction in unexplained variability is achieved by adjusting the response (to each treatment) according to slight differences in the covariate means as well as accounting for any underlying trends between the response and covariate(s). To do so, the extent to which the within treatment group small differences in covariate means between groups and treatment groups are essentially compared via differences in their \(y\)-intercepts. The total variation is thereafter partitioned into explained (using the deviations between the overall trend and trends approximated for each of the treatment groups) and unexplained components (using the deviations between the observations and the approximated within group trends). In this way, ANCOVA can be visualized as a regular ANOVA in which the group and overall means are replaced by group and overall trendlines. Importantly, it should be apparent that ANCOVA is only appropriate when each of the within group trends have the same slope and are thus parallel to one another and the overall trend. Furthermore, ANCOVA is not appropriate when the resulting adjustments must be extrapolated from a linear relationship outside the measured range of the covariate.
As an example, an experiment might be set up to investigate the energetic impacts of sexual vs parthenogenetic (egg development without fertilization) reproduction on leaf insect food consumption. To do so, researchers could measure the daily food intake of individual adult female leaf insects from female only (parthenogenetic) and mixed (sexual) populations. Unfortunately, the available individual leaf insects varied substantially in body size which was expected to increase the variability of daily food intake of treatment groups. Consequently, the researchers also measured the body mass of the individuals as a covariate, thereby providing a means by which daily food consumption could be standardized for body mass. ANCOVA attempts to reduce unexplained variability by standardising the response to the treatment by the effects of the specific covariate condition. Thus ANCOVA provides a means of exercising some statistical control over the variability when it is either not possible or not desirable to exercise experimental control (such as blocking or using otherwise homogeneous observations).
Null hypothesis
Factor A: the main treatment effect
- \(H_0(A):\mu_1(adj)=\mu_2(adj)=\ldots=\mu_i(adj)=\mu(adj)\)
The adjusted population group means are all equal. The mean of population \(1\) adjusted for the covariate is equal to that of population \(2\) adjusted for the covariate and so on, and thus all population means adjusted for the covariate are equal to an overall adjusted mean. If the effect of the \(i\)-th group is the difference between the \(i\)-th group adjusted mean and the overall adjusted mean (\(\alpha_i(adj)=\mu_i(adj)−\mu(adj)\)) then the \(H_0\) can alternatively be written as:
- \(H_0(A):\alpha_1(adj)=\alpha_2(adj)=\ldots=\alpha_i(adj)=0\)
The effect of each group equals zero. If one or more of the \(\alpha_i(adj)\) are different from zero (the response mean for this treatment differs from the overall response mean), the null hypothesis is not true, indicating that the treatment does affect the response variable.
Factor B: the covariate effect
- \(H_0(B):\beta_1(pooled)=0\)
The pooled population slope equals zero. Note, that this null hypothesis is rarely of much interest. It is precisely because of this nuisance relationship that ANCOVA designs are applied.
Linear models
One or more covariates can be incorporated into single factor, nested, factorial and partly nested designs in order to reduce the unexplained variation. Fundamentally, the covariate(s) are purely used to adjust the response values prior to the regular analysis. The difficulty is in determining the appropriate adjustments. Following is a list of the appropriate linear models and adjusted response calculations for a range of ANCOVA designs. Note that these linear models do not include interactions involving the covariates as these are assumed to be zero. The inclusion of these interaction terms is a useful means of testing the homogeneity of slopes assumption.
Single categorical and single covariate
Linear model: \(y_{ij}=\mu + \alpha_i + \beta(x_{ij}-\bar{x}) + \epsilon_{ij}\)
Adjustments: \(y_{ij(adj)}=y_{ij} - b(x_{ij} - \bar{x})\)
Single categorical and two covariates
Linear model: \(y_{ij}=\mu + \alpha_i + \beta_{YX}(x_{ij}-\bar{x}) + \beta_{YZ}(z_{ij}-\bar{z}) + \epsilon_{ij}\)
Adjustments: \(y_{ij(adj)}=y_{ij} - b_{YX}(x_{ij} - \bar{x}) - b_{YZ}(z_{ij} - \bar{z})\)
Factorial designs
Linear model: \(y_{ij}=\mu + \alpha_i + \gamma_j + (\alpha\gamma)_{ij}+ \beta(x_{ijk}-\bar{x}) + \epsilon_{ijk}\)
Adjustments: \(y_{ijk(adj)}=y_{ijk} - b(x_{ijk} - \bar{x})\)
Nested designs
Linear model: \(y_{ijk}=\mu + \alpha_i + \gamma_{j(i)} + \beta(x_{ijk}-\bar{x}) + \epsilon_{ijk}\)
Adjustments: \(y_{ijk(adj)}=y_{ijk} - b(x_{ijk} - \bar{x})\)
Partly nested designs
Linear model: \(y_{ijkl}=\mu + \alpha_i + \gamma_{j(i)} + \delta_k + (\alpha\delta)_{ik} + (\gamma\delta)_{j(i)k} + \beta(x_{ijk}-\bar{x}) + \epsilon_{ijkl}\)
Adjustments: \(y_{ijk(adj)}=y_{ijkl} - b_{between}(x_{i} - \bar{x}) - b_{within}(x_{ijk} - \bar{x}_i)\)
Analysis of variance
In ANCOVA, the total variability of the response variable is sequentially partitioned into components explained by each of the model terms, starting with the covariate and is therefore equivalent to performing a regular analysis of variance on the response variables that have been adjusted for the covariate. The appropriate unexplained residuals and therefore the appropriate F-ratios for each factor differ according to the different null hypotheses associated with different linear models as well as combinations of fixed and random factors in the model (see the following tables). Note that since the covariate levels measured are typically different for each group, ANCOVA designs are inherently non-orthogonal (unbalanced). Consequently, sequential (Type I sums of squares) should not be used. For very simple Ancova designs that incorporate a single categorical and single covariate, Type I sums of squares can be used provided the covariate appears in the linear model first (and thus is partitioned out last) as we are typically not interested in estimating this effect.
> ancova_table
df MS F-ratio (A&B fixed) F-ratio (B fixed)
Factor A "a-1" "MS A" "(MS A)/(MS res)" "(MS A)/(MS res)"
Factor B "1" "MS B" "(MS B)/(MS res)" "(MS B)/(MS res)"
Factor AB "a-1" "MS AB" "(MS AB)/(MS res)" "(MS AB)/(MS res)"
Residual "(n-2)a" "MS res" "" "" The corresponding R syntax is given below.
> anova(lm(DV ~ B * A, dataset))
> # OR
> anova(aov(DV ~ B * A, dataset))
> # OR (make sure not using treatment contrasts)
> Anova(lm(DV ~ B * A, dataset), type = "III")Assumptions
As ANCOVA designs are essentially regular ANOVA designs that are first adjusted (centered) for the covariate(s), ANCOVA designs inherit all of the underlying assumptions of the appropriate ANOVA design. Specifically, hypothesis tests assume that:
The appropriate residuals are normally distributed. Boxplots using the appropriate scale of replication (reflecting the appropriate residuals/F-ratio denominator, see the above tables) should be used to explore normality. Scale transformations are often useful.
The appropriate residuals are equally varied. Boxplots and plots of means against variance (using the appropriate scale of replication) should be used to explore the spread of values. Residual plots should reveal no patterns. Scale transformations are often useful.
The appropriate residuals are independent of one another.
The relationship between the response variable and the covariate should be linear. Linearity can be explored using scatterplots and residual plots should reveal no patterns.
For repeated measures and other designs in which treatment levels within blocks can not be be randomly ordered, the variance/covariance matrix is assumed to display sphericity.
For designs that utilise blocking, it is assumed that there are no block by within block interactions.
Homogeneity of Slopes
In addition to the above assumptions, ANCOVA designs also assume that slopes of relationships between the response variable and the covariate(s) are the same for each treatment level (group). That is, all the trends are parallel. If the individual slopes deviate substantially from each other (and thus the overall slope), then adjustments made to each of the observations are nonsensical. This situation is analogous to an interaction between two or more factors. In ANCOVA, interactions involving the covariate suggest that the nature of the relationship between the response and the covariate differs between the levels of the categorical treatment. More importantly, they also indicate that whether or not there is an effect of the treatment depends on what range of the covariate you are focussed on. Clearly then, it is not possible to make conclusions about the main effects of treatments in the presence of such interactions. The assumption of homogeneity of slopes can be examined via interaction plots or more formally, by testing hypotheses about the interactions between categorical variables and the covariate(s). There are three broad approaches for dealing with ANCOVA designs with heterogeneous slopes and selection depends on the primary focus of the study.
When the primary objective of the analysis is to investigate the effects of categorical treatments, it is possible to adopt an approach similar to that taken when exploring interactions in multiple regression. The effect of treatments can be examined at specific values of the covariate (such as the mean and \(\pm\) one standard deviation). This approach is really only useful at revealing broad shifts in patterns over the range of the covariate and if the selected values of the covariate do not have some inherent clinical meaning (selected arbitrarily), then the outcomes can be of only limited clinical interest.
Alternatively, the Johnson-Neyman technique (or Wilxon modification thereof) procedure indicates the ranges of the covariate over which the individual regression lines of pairs of treatment groups overlap or cross. Although less powerful than the previous approach, the Wilcox(J-N) procedure has the advantage of revealing the important range (ranges for which the groups are different and not different) of the covariate rather than being constrained by specific levels selected.
Use contrast treatments to split up the interaction term into its constituent contrasts for each level of the treatment. Essentially this compares each of the treatment level slopes to the slope from the “control” group and is useful if the primary focus is on the relationships between the response and the covariate.
Similar covariate ranges
Adjustments made to the response means in an attempt to statistically account for differences in the covariate involve predicting mean response values along displaced linear relationships between the overall response and covariate variables. The degree of trend displacement for any given group is essentially calculated by multiplying the overall regression slope by the degree of difference between the overall covariate mean and the mean of the covariate for that group. However, when the ranges of the covariate within each of the groups differ substantially from one another, these adjustments are effectively extrapolations and therefore of unknown reliability. If a simple ANOVA of the covariate modelled against the categorical factor indicates that the covariate means differ significantly between groups, it may be necessary to either remove extreme observations or reconsider the analysis.
Robust ANCOVA
ANCOVA based on rank transformed data can be useful for accommodating data with numerous problematic outliers. Nevertheless, problems about the difficulties of detecting interactions from rank transformed data, obviously have implications for inferential tests of homogeneity of slopes. Randomisation tests that maintain response0covariate pairs and repeatedly randomise these observations amongst the levels of the treatments can also be useful, particularly when there is doubt over the independence of observations. Both planned and unplanned comparisons follow those of other ANOVA chapters without any real additional complications. Notably, recent implementations of the Tukey’s test (within R) accommodate unbalanced designs and thus negate the need for some of the more complicated and specialised techniques that have been highlighted in past texts.
Data generation
Consider an experimental design aimed at exploring the effects of a categorical variable with three levels (Group A, Group B and Group C) on a response. From previous studies, we know that the response is influenced by another variable (covariate). Unfortunately, it was not possible to ensure that all sampling units were the same degree of the covariate. Therefore, in an attempt to account for this anticipated extra source of variability, we measured the level of the covariate for each sampling unit. Actually, in allocating treatments to the various treatment groups, we tried to ensure a similar mean and range of the covariate within each group.
> set.seed(123)
> n <- 10
> p <- 3
> A.eff <- c(40, -15, -20)
> beta <- -0.45
> sigma <- 4
> B <- rnorm(n * p, 0, 15)
> A <- gl(p, n, lab = paste("Group", LETTERS[1:3]))
> mm <- model.matrix(~A + B)
> data <- data.frame(A = A, B = B, Y = as.numeric(c(A.eff, beta) %*% t(mm)) + rnorm(n * p, 0, 4))
> data$B <- data$B + 20
> head(data)
A B Y
1 Group A 11.59287 45.48907
2 Group A 16.54734 40.37341
3 Group A 43.38062 33.05922
4 Group A 21.05763 43.03660
5 Group A 21.93932 42.41363
6 Group A 45.72597 31.17787Exploratory data analysis
> library(car)
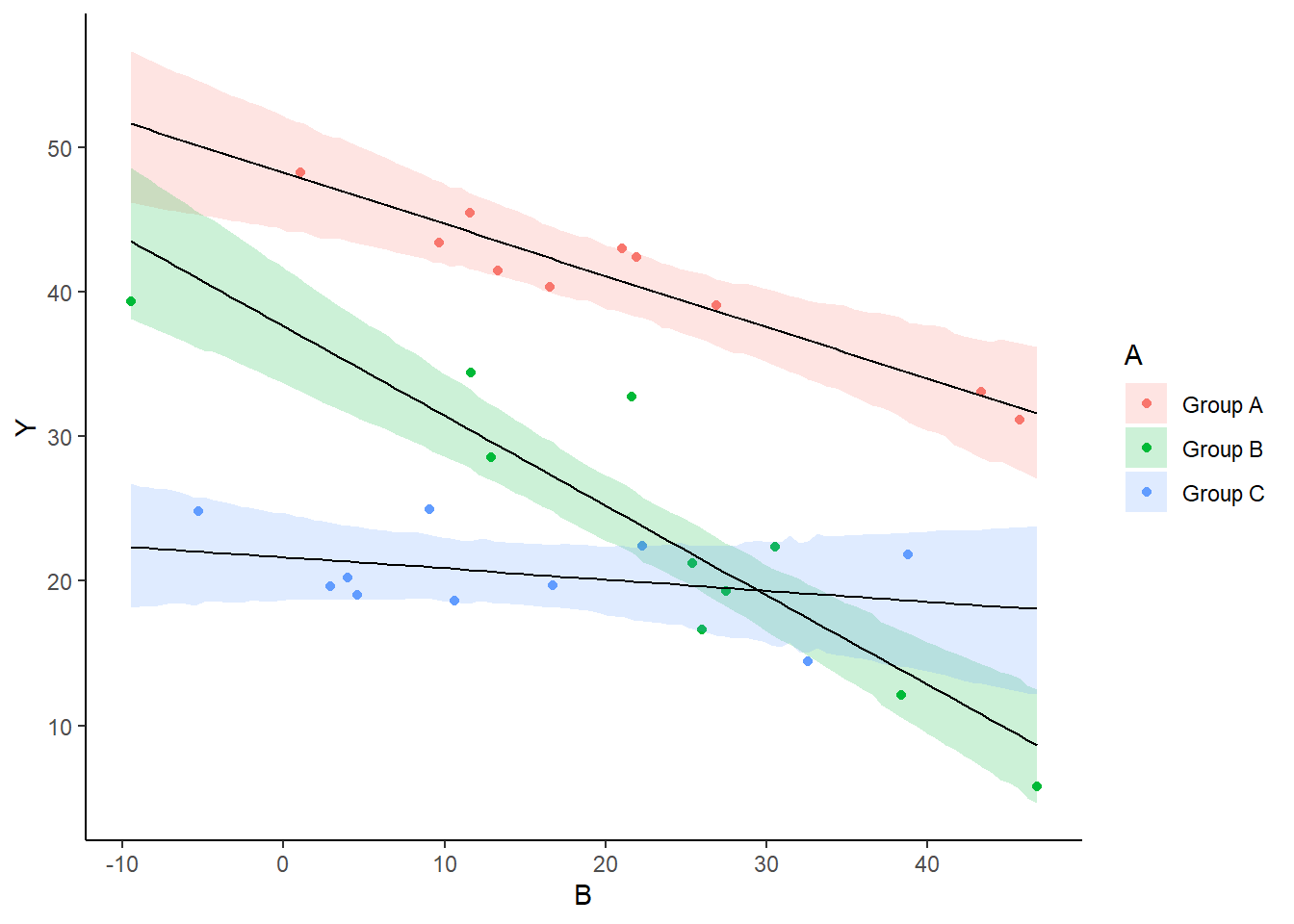
> scatterplot(Y ~ B | A, data = data)
>
> boxplot(Y ~ A, data)
>
> # OR via ggplot
> library(ggplot2)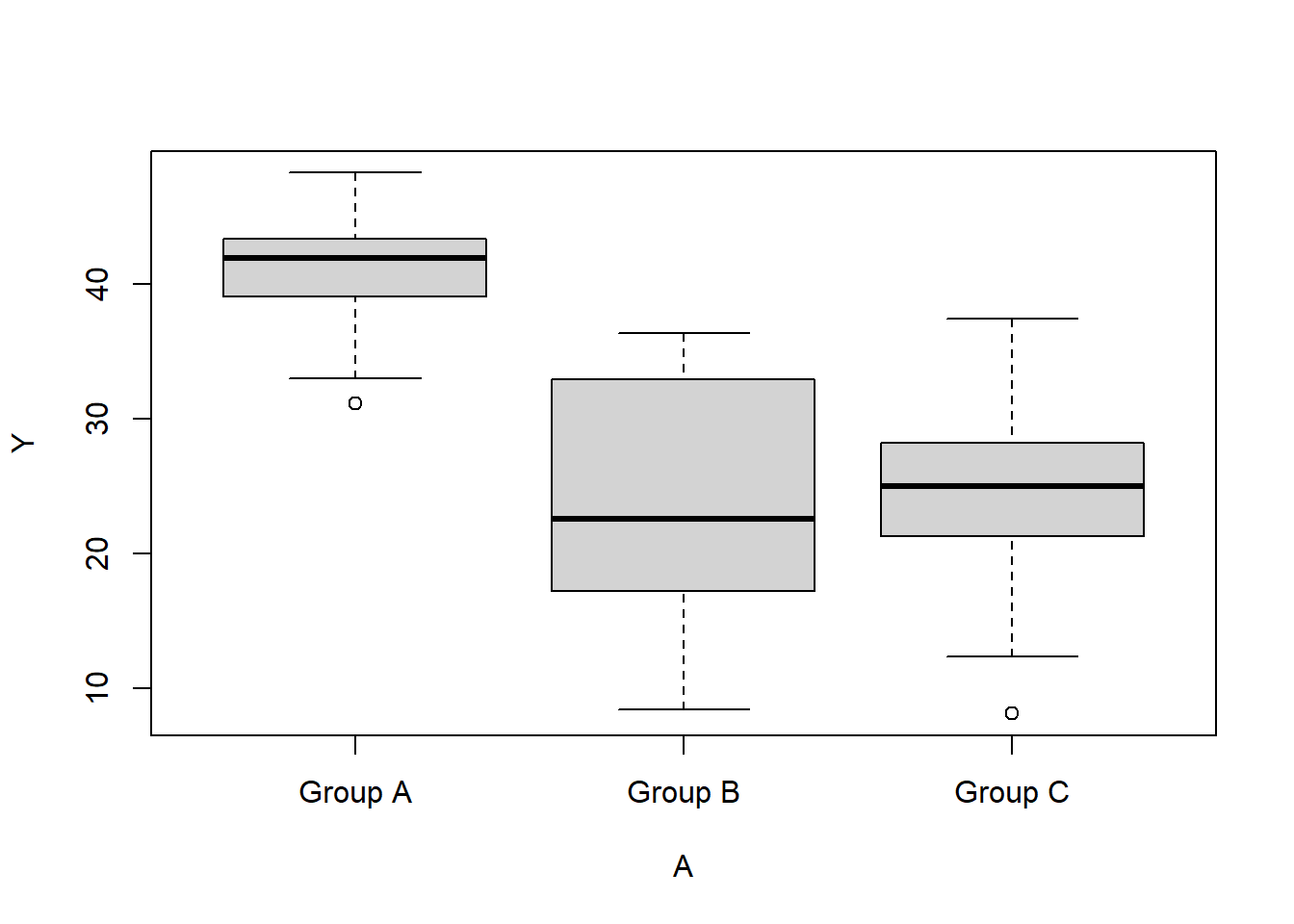
> ggplot(data, aes(y = Y, x = B, group = A)) + geom_point() + geom_smooth(method = "lm")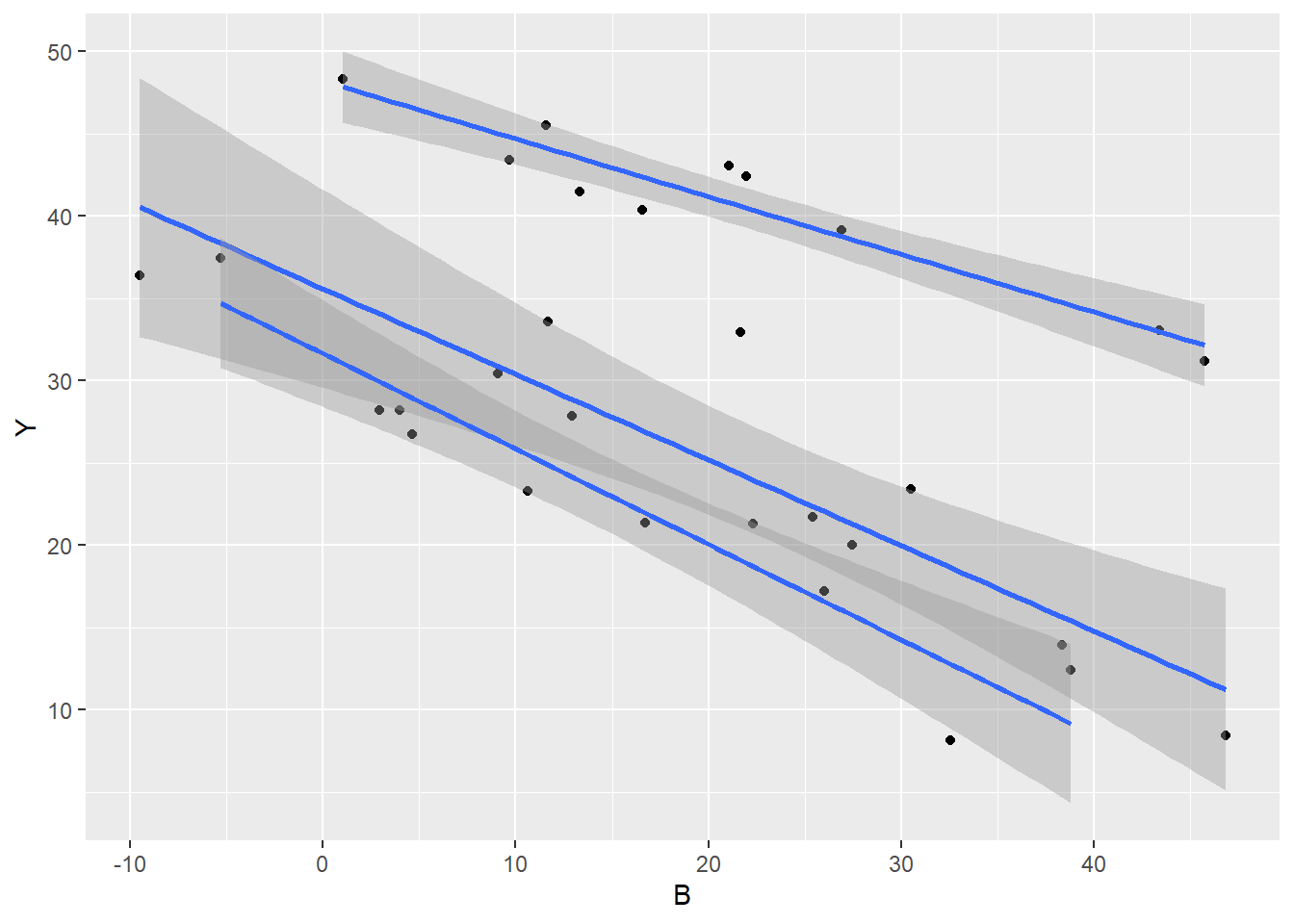
>
> ggplot(data, aes(y = Y, x = A)) + geom_boxplot()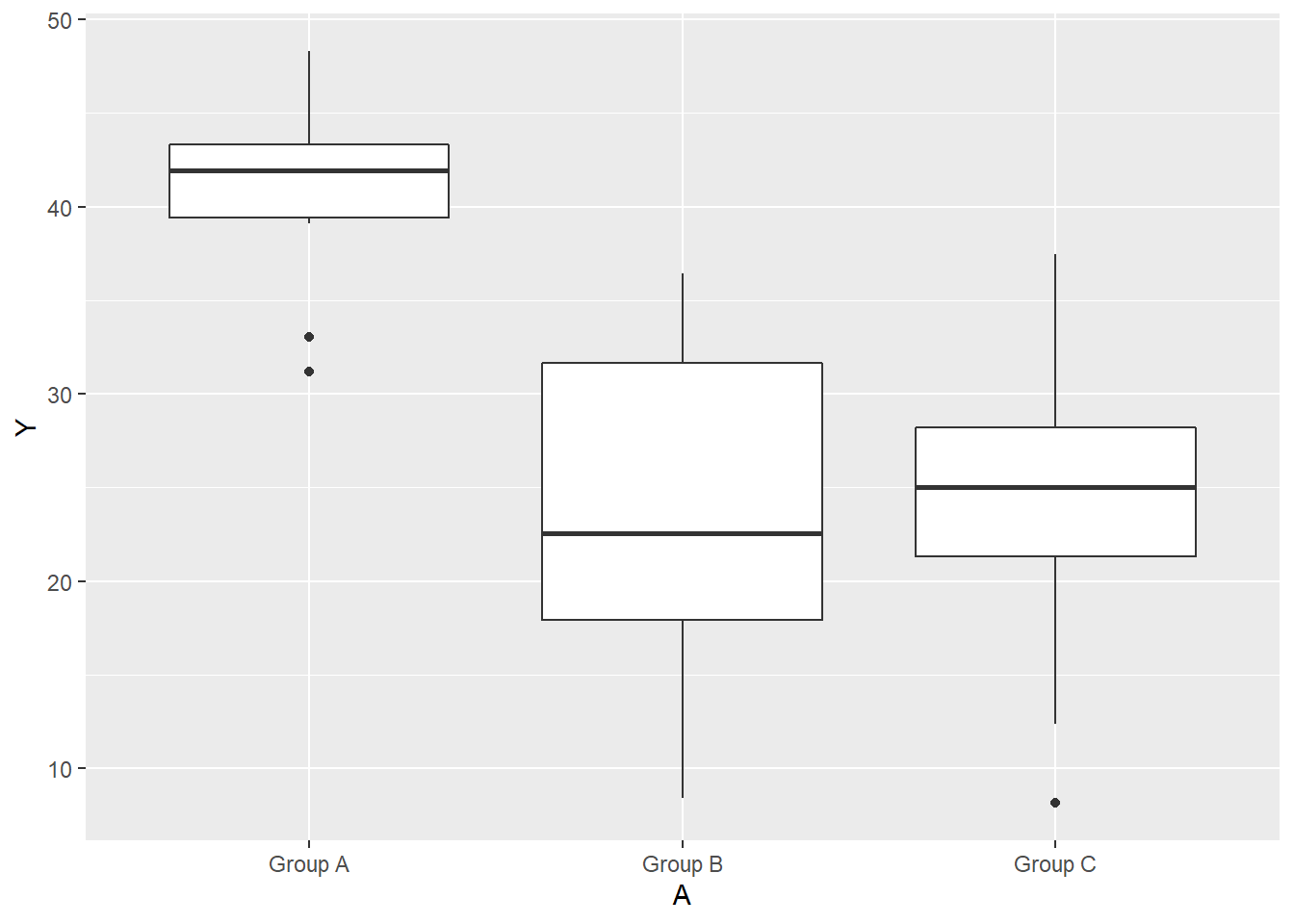
Conclusions
There is no evidence of obvious non-normality. The assumption of linearity seems reasonable. The variability of the three groups seems approximately equal. The slopes (\(Y\) vs B trends) appear broadly similar for each treatment group.
We can explore inferential evidence of unequal slopes by examining estimated effects of the interaction between the categorical variable and the covariate. Note, pay no attention to the main effects - only the interaction. Even though I intend to illustrate Bayesian analyses here, for such a simple model, it is considerably simpler to use traditional OLS for testing for the presence of an interaction.
> anova(lm(Y ~ B * A, data = data))
Analysis of Variance Table
Response: Y
Df Sum Sq Mean Sq F value Pr(>F)
B 1 989.99 989.99 92.6782 1.027e-09 ***
A 2 2320.05 1160.02 108.5956 9.423e-13 ***
B:A 2 51.36 25.68 2.4041 0.1118
Residuals 24 256.37 10.68
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1There is very little evidence to suggest that the assumption of equal slopes will be inappropriate.
Model fitting
The observed response (\(y_i\)) are assumed to be drawn from a normal distribution with a given mean (\(\mu\)) and standard deviation (\(\sigma\)). The expected values are themselves determined by the linear predictor (\(\boldsymbol X \boldsymbol \beta\)). In this case, \(\boldsymbol \beta\) represents the vector of \(\beta\)’s - the intercept associated with the first group, the (effects) differences between this intercept and the intercepts for each other group as well as the slope associated with the continuous covariate. \(\boldsymbol X\) is the model matrix. MCMC sampling requires priors on all parameters. We will employ weakly informative priors. Specifying ‘uninformative’ priors is always a bit of a balancing act. If the priors are too vague (wide) the MCMC sampler can wander off into nonscence areas of likelihood rather than concentrate around areas of highest likelihood (desired when wanting the outcomes to be largely driven by the data). On the other hand, if the priors are too strong, they may have an influence on the parameters. In such a simple model, this balance is very forgiving - it is for more complex models that prior choice becomes more important. For this simple model, we will go with zero-centered Gaussian (normal) priors with relatively large standard deviations (\(100\)) for both the intercept and the treatment effect and a wide half-cauchy (\(\text{scale}=5\)) for the standard deviation.
\[y_i \sim N(\mu_i,\sigma), \]
where \(\mu_i=\beta_0 +\boldsymbol \beta \boldsymbol X\). The assumed priors are: \(\beta \sim N(0,100)\) and \(\sigma \sim \text{Cauchy}(0,5)\). Note, exploratory data analysis suggests that while the intercept (intercept of Group A) and categorical predictor effects (differences between intercepts of each of the Group and Group A’s intercept) could be drawn from a similar distribution (with mean in the \(10\)’s and variances in the \(100\)’s), the slope (effect associated with Group A linear relationship) is likely to be an order of magnitude less. We might therefore be tempted to provide different priors for the intercept, categorical effects and slope effect. For a simple model such as this, it is unlikely to be necessary. However, for more complex models, where prior specification becomes more critical, separate priors would probably be necessary. We proceed to code the model into Stan.
> modelString = "
+ data {
+ int<lower=1> n;
+ int<lower=1> nX;
+ vector [n] y;
+ matrix [n,nX] X;
+ }
+ parameters {
+ vector[nX] beta;
+ real<lower=0> sigma;
+ }
+ transformed parameters {
+ vector[n] mu;
+
+ mu = X*beta;
+ }
+ model {
+ //Likelihood
+ y~normal(mu,sigma);
+
+ //Priors
+ beta ~ normal(0,100);
+ sigma~cauchy(0,5);
+ }
+ generated quantities {
+ vector[n] log_lik;
+
+ for (i in 1:n) {
+ log_lik[i] = normal_lpdf(y[i] | mu[i], sigma);
+ }
+ }
+
+ "
> ## write the model to a stan file
> writeLines(modelString, con = "ancovaModel.stan")Arrange the data as a list (as required by Stan). As input, Stan will need to be supplied with: the response variable, the predictor variable, the total number of observed items. This all needs to be contained within a list object. We will create two data lists, one for each of the hypotheses.
> Xmat <- model.matrix(~A + B, data)
> data.list <- with(data, list(y = Y, X = Xmat, nX = ncol(Xmat), n = nrow(data)))Define the nodes (parameters and derivatives) to monitor and chain parameters.
> params <- c("beta", "sigma", "log_lik")
> nChains = 2
> burnInSteps = 500
> thinSteps = 1
> numSavedSteps = 2000 #across all chains
> nIter = ceiling(burnInSteps + (numSavedSteps * thinSteps)/nChains)
> nIter
[1] 1500Now compile and run the Stan code via the rstan interface. Note that the first time stan is run after the rstan package is loaded, it is often necessary to run any kind of randomization function just to initiate the .Random.seed variable.
> library(rstan)During the warmup stage, the No-U-Turn sampler (NUTS) attempts to determine the optimum stepsize - the stepsize that achieves the target acceptance rate (\(0.8\) or \(80\)% by default) without divergence (occurs when the stepsize is too large relative to the curvature of the log posterior and results in approximations that are likely to diverge and be biased) - and without hitting the maximum treedepth (\(10\)). At each iteration of the NUTS algorithm, the number of leapfrog steps doubles (as it increases the treedepth) and only terminates when either the NUTS criterion are satisfied or the tree depth reaches the maximum (\(10\) by default).
> data.rstan <- stan(data = data.list, file = "ancovaModel.stan", chains = nChains, pars = params,
+ iter = nIter, warmup = burnInSteps, thin = thinSteps)
SAMPLING FOR MODEL 'ancovaModel' NOW (CHAIN 1).
Chain 1:
Chain 1: Gradient evaluation took 0 seconds
Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Chain 1: Adjust your expectations accordingly!
Chain 1:
Chain 1:
Chain 1: Iteration: 1 / 1500 [ 0%] (Warmup)
Chain 1: Iteration: 150 / 1500 [ 10%] (Warmup)
Chain 1: Iteration: 300 / 1500 [ 20%] (Warmup)
Chain 1: Iteration: 450 / 1500 [ 30%] (Warmup)
Chain 1: Iteration: 501 / 1500 [ 33%] (Sampling)
Chain 1: Iteration: 650 / 1500 [ 43%] (Sampling)
Chain 1: Iteration: 800 / 1500 [ 53%] (Sampling)
Chain 1: Iteration: 950 / 1500 [ 63%] (Sampling)
Chain 1: Iteration: 1100 / 1500 [ 73%] (Sampling)
Chain 1: Iteration: 1250 / 1500 [ 83%] (Sampling)
Chain 1: Iteration: 1400 / 1500 [ 93%] (Sampling)
Chain 1: Iteration: 1500 / 1500 [100%] (Sampling)
Chain 1:
Chain 1: Elapsed Time: 0.077 seconds (Warm-up)
Chain 1: 0.049 seconds (Sampling)
Chain 1: 0.126 seconds (Total)
Chain 1:
SAMPLING FOR MODEL 'ancovaModel' NOW (CHAIN 2).
Chain 2:
Chain 2: Gradient evaluation took 0.001 seconds
Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 10 seconds.
Chain 2: Adjust your expectations accordingly!
Chain 2:
Chain 2:
Chain 2: Iteration: 1 / 1500 [ 0%] (Warmup)
Chain 2: Iteration: 150 / 1500 [ 10%] (Warmup)
Chain 2: Iteration: 300 / 1500 [ 20%] (Warmup)
Chain 2: Iteration: 450 / 1500 [ 30%] (Warmup)
Chain 2: Iteration: 501 / 1500 [ 33%] (Sampling)
Chain 2: Iteration: 650 / 1500 [ 43%] (Sampling)
Chain 2: Iteration: 800 / 1500 [ 53%] (Sampling)
Chain 2: Iteration: 950 / 1500 [ 63%] (Sampling)
Chain 2: Iteration: 1100 / 1500 [ 73%] (Sampling)
Chain 2: Iteration: 1250 / 1500 [ 83%] (Sampling)
Chain 2: Iteration: 1400 / 1500 [ 93%] (Sampling)
Chain 2: Iteration: 1500 / 1500 [100%] (Sampling)
Chain 2:
Chain 2: Elapsed Time: 0.078 seconds (Warm-up)
Chain 2: 0.054 seconds (Sampling)
Chain 2: 0.132 seconds (Total)
Chain 2:
>
> print(data.rstan, par = c("beta", "sigma"))
Inference for Stan model: ancovaModel.
2 chains, each with iter=1500; warmup=500; thin=1;
post-warmup draws per chain=1000, total post-warmup draws=2000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
beta[1] 50.93 0.05 1.44 48.08 49.99 50.92 51.88 53.88 978 1
beta[2] -16.14 0.05 1.58 -19.21 -17.21 -16.16 -15.08 -12.96 1216 1
beta[3] -20.57 0.05 1.62 -23.68 -21.69 -20.56 -19.47 -17.38 1268 1
beta[4] -0.48 0.00 0.04 -0.57 -0.51 -0.48 -0.45 -0.39 1189 1
sigma 3.58 0.02 0.52 2.76 3.22 3.51 3.88 4.69 1177 1
Samples were drawn using NUTS(diag_e) at Thu Jul 08 21:55:10 2021.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).MCMC diagnostics
In addition to the regular model diagnostic checks (such as residual plots), for Bayesian analyses, it is necessary to explore the characteristics of the MCMC chains and the sampler in general. Recall that the purpose of MCMC sampling is to replicate the posterior distribution of the model likelihood and priors by drawing a known number of samples from this posterior (thereby formulating a probability distribution). This is only reliable if the MCMC samples accurately reflect the posterior. Unfortunately, since we only know the posterior in the most trivial of circumstances, it is necessary to rely on indirect measures of how accurately the MCMC samples are likely to reflect the likelihood. I will briefly outline the most important diagnostics.
Traceplots for each parameter illustrate the MCMC sample values after each successive iteration along the chain. Bad chain mixing (characterised by any sort of pattern) suggests that the MCMC sampling chains may not have completely traversed all features of the posterior distribution and that more iterations are required to ensure the distribution has been accurately represented.
Autocorrelation plot for each parameter illustrate the degree of correlation between MCMC samples separated by different lags. For example, a lag of \(0\) represents the degree of correlation between each MCMC sample and itself (obviously this will be a correlation of \(1\)). A lag of \(1\) represents the degree of correlation between each MCMC sample and the next sample along the chain and so on. In order to be able to generate unbiased estimates of parameters, the MCMC samples should be independent (uncorrelated).
Potential scale reduction factor (Rhat) statistic for each parameter provides a measure of sampling efficiency/effectiveness. Ideally, all values should be less than \(1.05\). If there are values of \(1.05\) or greater it suggests that the sampler was not very efficient or effective. Not only does this mean that the sampler was potentially slower than it could have been but, more importantly, it could indicate that the sampler spent time sampling in a region of the likelihood that is less informative. Such a situation can arise from either a misspecified model or overly vague priors that permit sampling in otherwise nonscence parameter space.
Prior to examining the summaries, we should have explored the convergence diagnostics. We use the package mcmcplots to obtain density and trace plots.
> library(mcmcplots)
> s = as.array(data.rstan)
> wch = grep("beta", dimnames(s)$parameters)
> s = s[, , wch]
> mcmc <- do.call(mcmc.list, plyr:::alply(s[, , -(length(s[1, 1, ]))], 2, as.mcmc))
> denplot(mcmc, parms = c("beta"))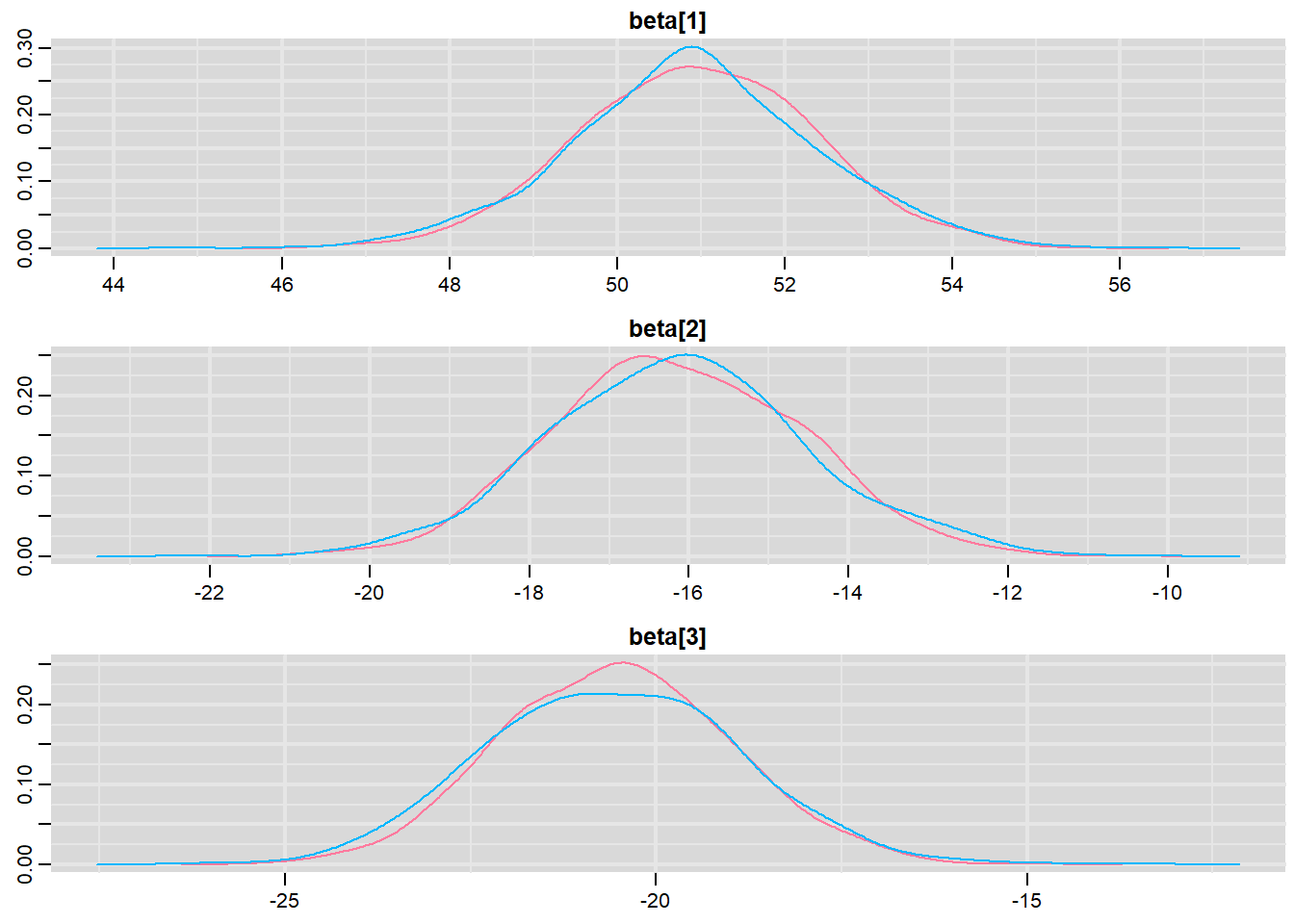
> traplot(mcmc, parms = c("beta"))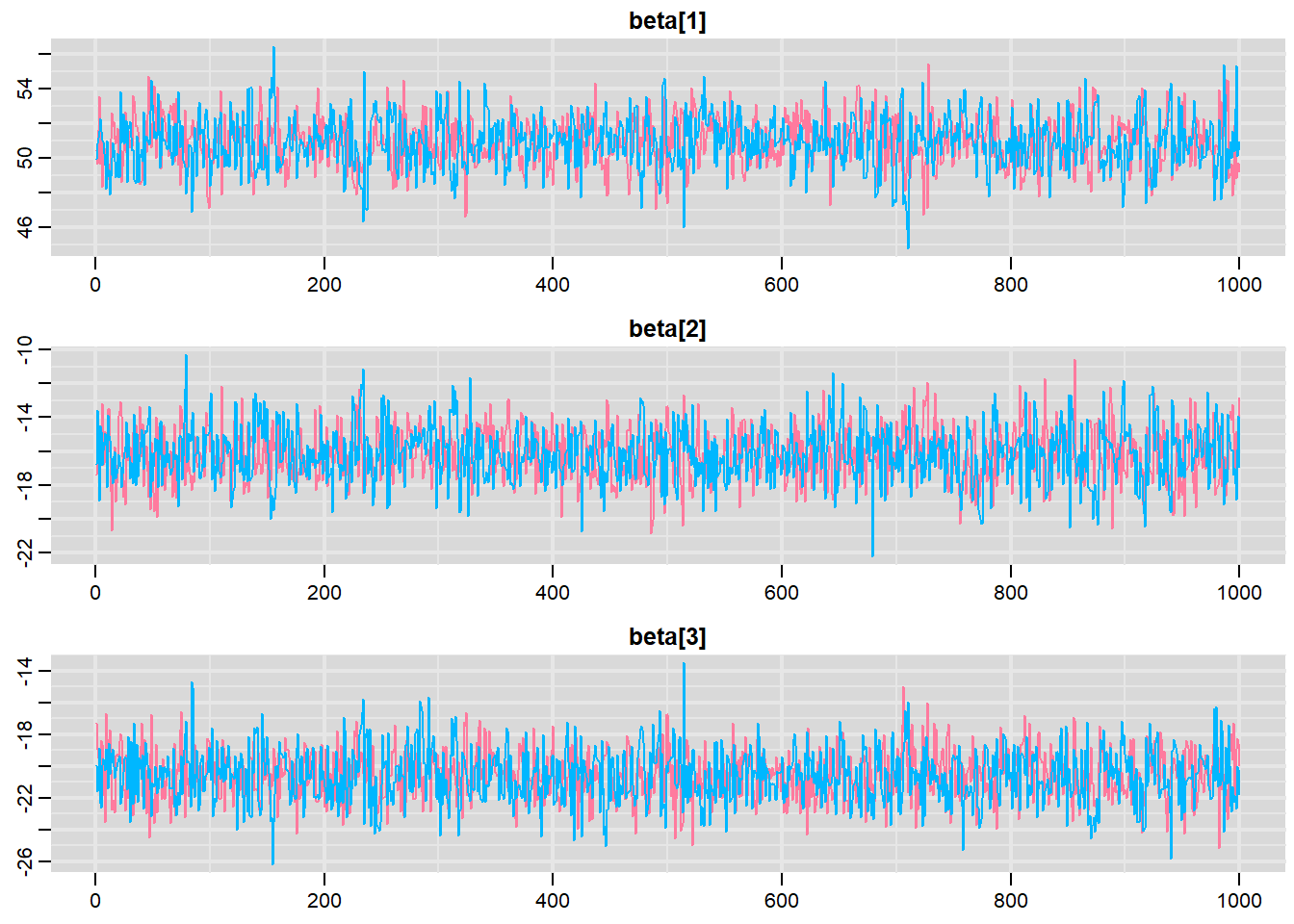
These plots show no evidence that the chains have not reasonably traversed the entire multidimensional parameter space.
> #Raftery diagnostic
> raftery.diag(mcmc)
$`1`
Quantile (q) = 0.025
Accuracy (r) = +/- 0.005
Probability (s) = 0.95
You need a sample size of at least 3746 with these values of q, r and s
$`2`
Quantile (q) = 0.025
Accuracy (r) = +/- 0.005
Probability (s) = 0.95
You need a sample size of at least 3746 with these values of q, r and sThe Raftery diagnostics for each chain estimate that we would require no more than \(5000\) samples to reach the specified level of confidence in convergence. As we have \(10500\) samples, we can be confidence that convergence has occurred.
> #Autocorrelation diagnostic
> stan_ac(data.rstan, pars = c("beta"))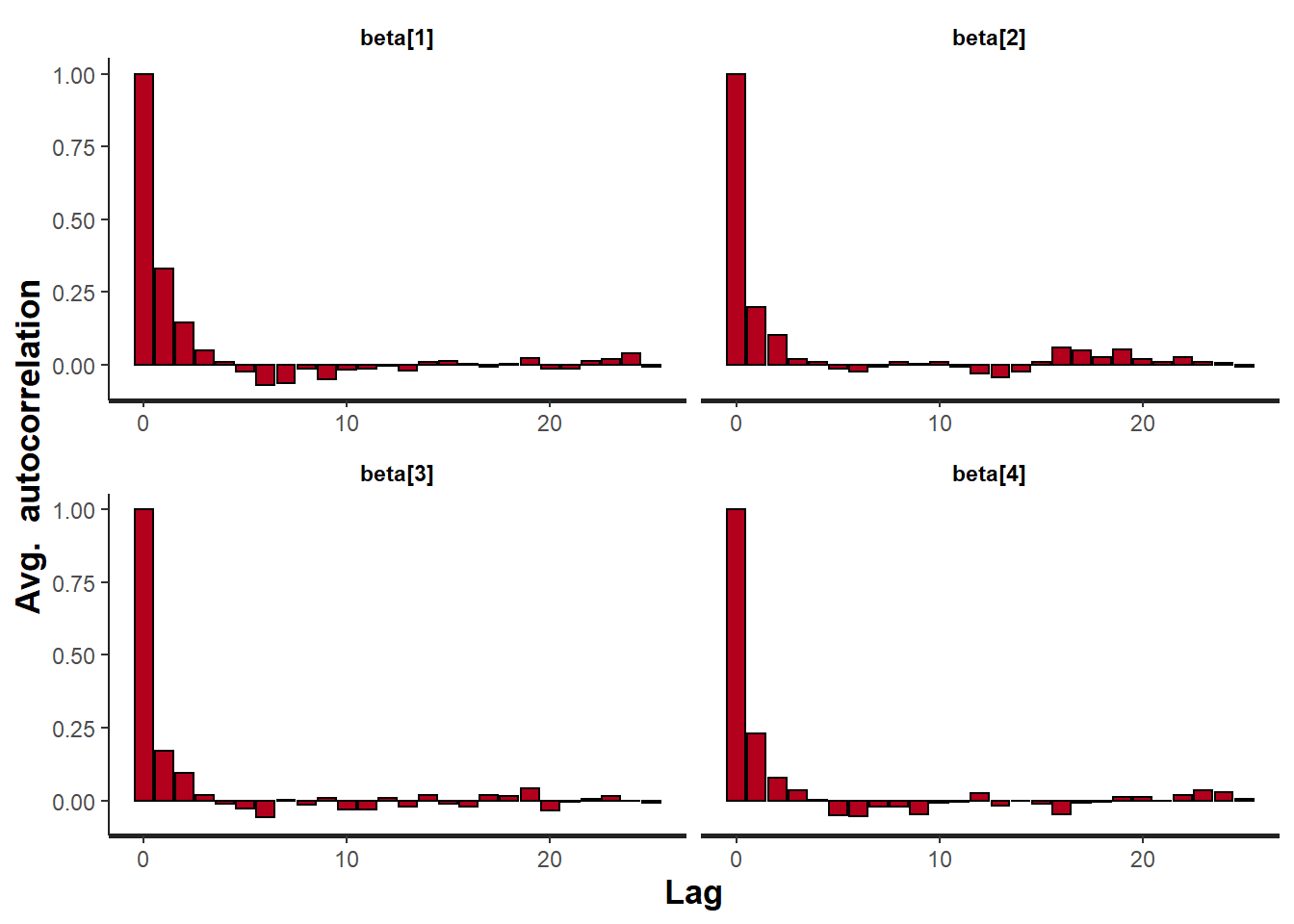
A lag of 10 appears to be sufficient to avoid autocorrelation (poor mixing).
> stan_rhat(data.rstan, pars = c("beta"))
> stan_ess(data.rstan, pars = c("beta"))
Rhat and effective sample size. In this instance, most of the parameters have reasonably high effective samples and thus there is likely to be a good range of values from which to estimate paramter properties.
Model validation
Model validation involves exploring the model diagnostics and fit to ensure that the model is broadly appropriate for the data. As such, exploration of the residuals should be routine. Ideally, a good model should also be able to predict the data used to fit the model. Residuals are not computed directly within rstan However, we can calculate them manually form the posteriors.
> library(dplyr)
> mcmc = as.data.frame(data.rstan) %>% dplyr:::select(contains("beta"),
+ sigma) %>% as.matrix
> # generate a model matrix
> newdata = data
> Xmat = model.matrix(~A + B, newdata)
> ## get median parameter estimates
> coefs = apply(mcmc[, 1:4], 2, median)
> fit = as.vector(coefs %*% t(Xmat))
> resid = data$Y - fit
> ggplot() + geom_point(data = NULL, aes(y = resid, x = fit)) + theme_classic()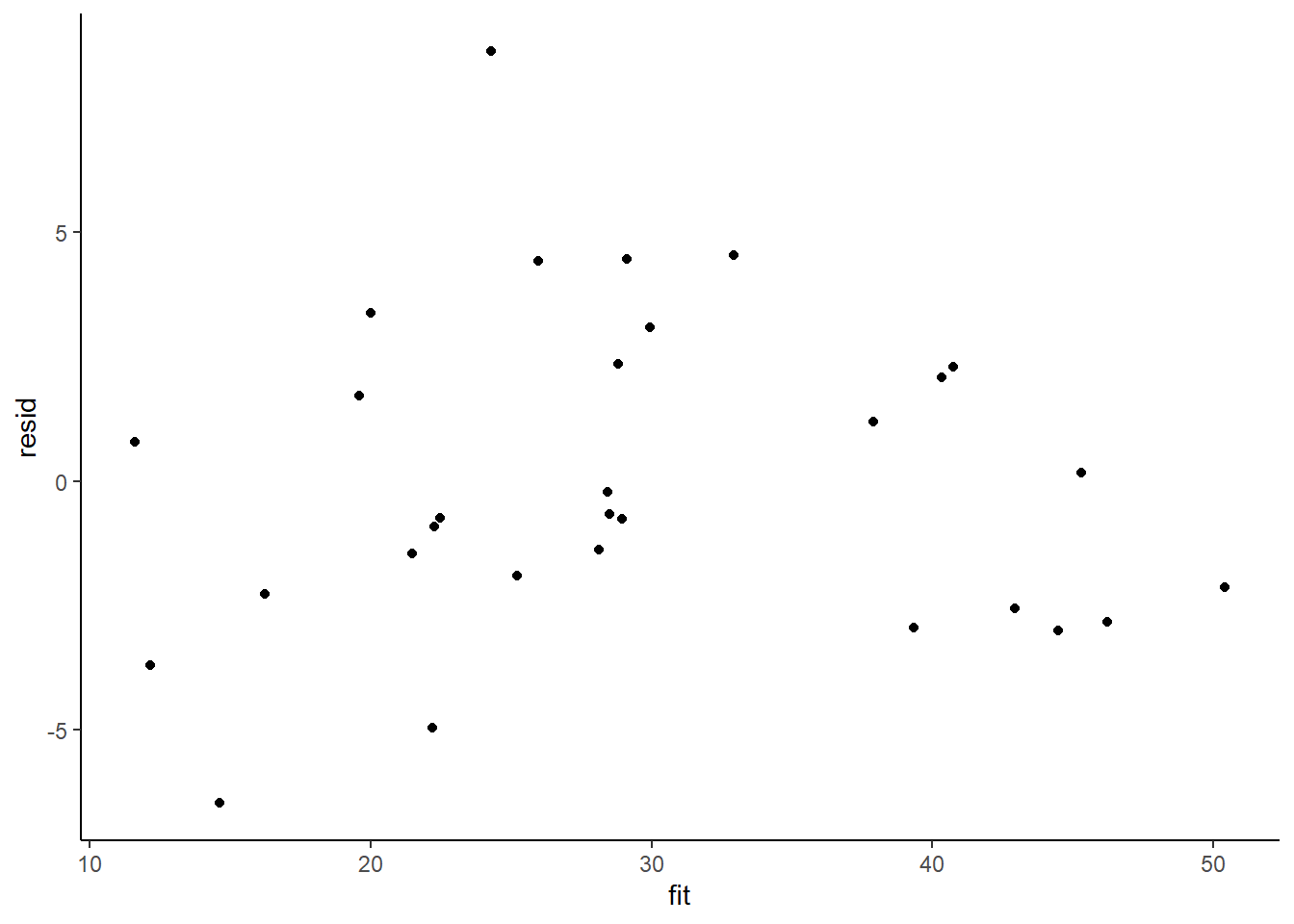
Residuals against predictors
> library(tidyr)
> mcmc = as.data.frame(data.rstan) %>% dplyr:::select(contains("beta"),
+ sigma) %>% as.matrix
> # generate a model matrix
> newdata = newdata
> Xmat = model.matrix(~A + B, newdata)
> ## get median parameter estimates
> coefs = apply(mcmc[, 1:4], 2, median)
> fit = as.vector(coefs %*% t(Xmat))
> resid = data$Y - fit
> newdata = newdata %>% cbind(fit, resid)
> ggplot(newdata) + geom_point(aes(y = resid, x = A)) + theme_classic()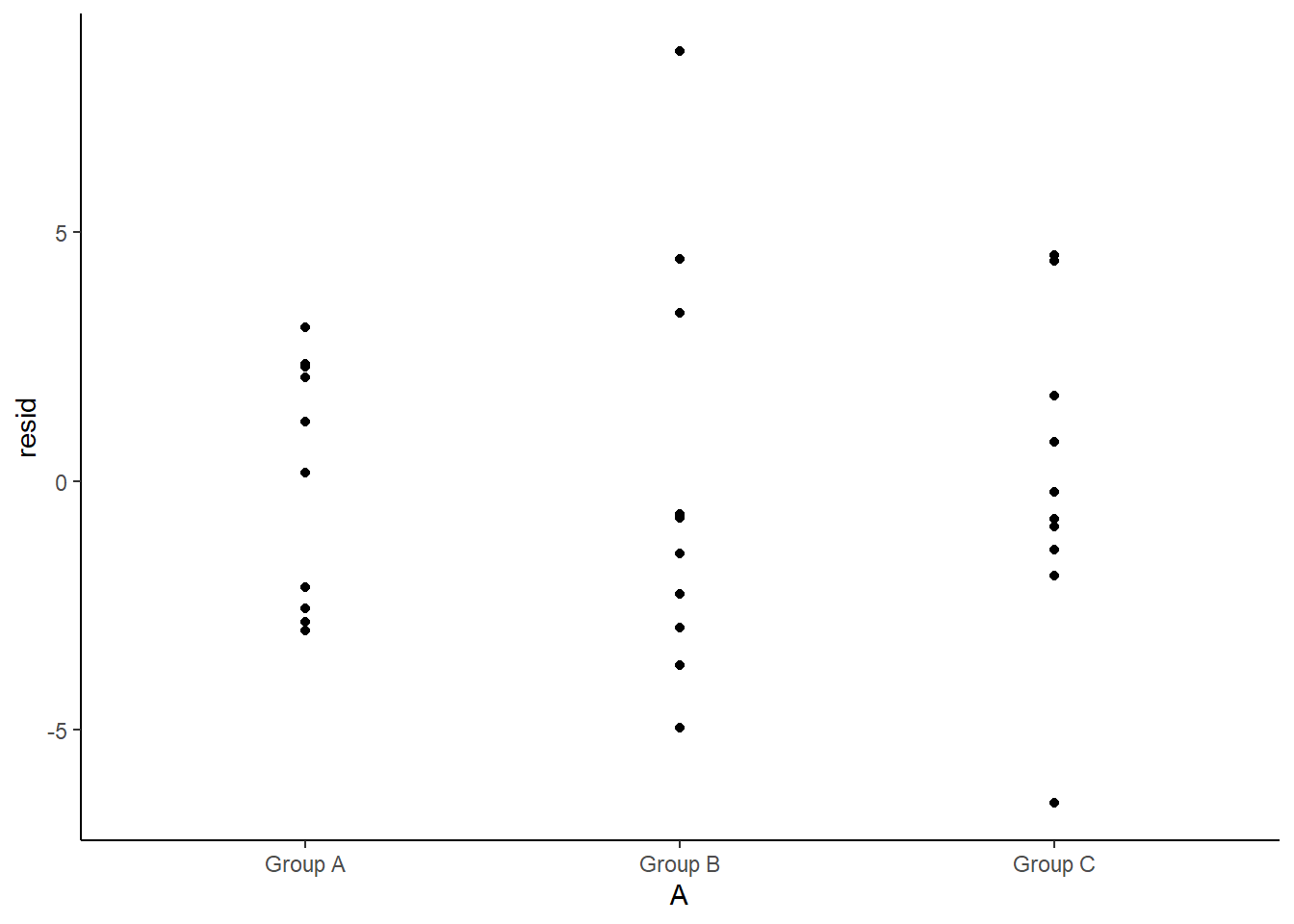
>
> ggplot(newdata) + geom_point(aes(y = resid, x = B)) + theme_classic()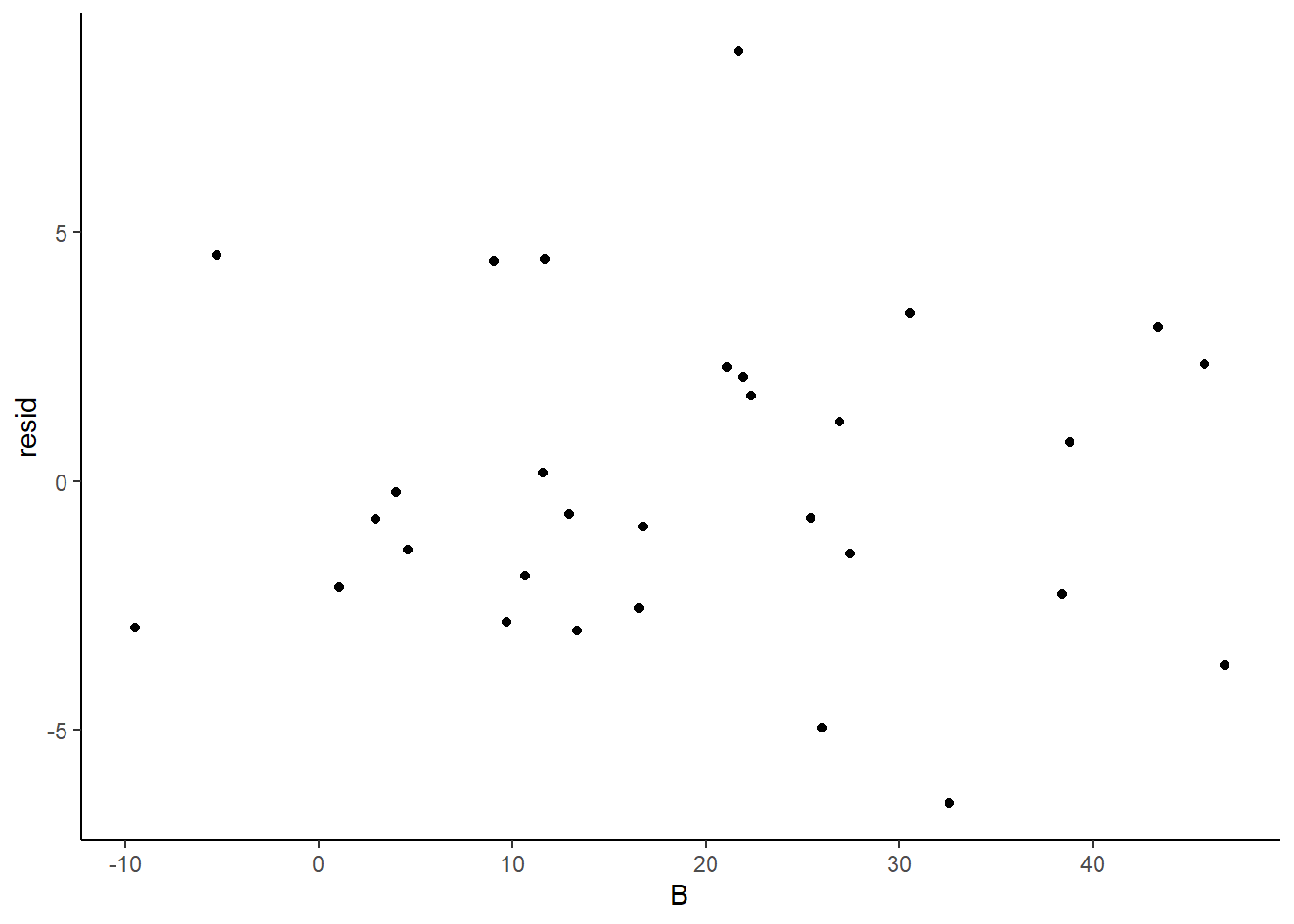
And now for studentised residuals
> mcmc = as.data.frame(data.rstan) %>% dplyr:::select(contains("beta"),
+ sigma) %>% as.matrix
> # generate a model matrix
> newdata = data
> Xmat = model.matrix(~A + B, newdata)
> ## get median parameter estimates
> coefs = apply(mcmc[, 1:4], 2, median)
> fit = as.vector(coefs %*% t(Xmat))
> resid = data$Y - fit
> sresid = resid/sd(resid)
> ggplot() + geom_point(data = NULL, aes(y = sresid, x = fit)) + theme_classic()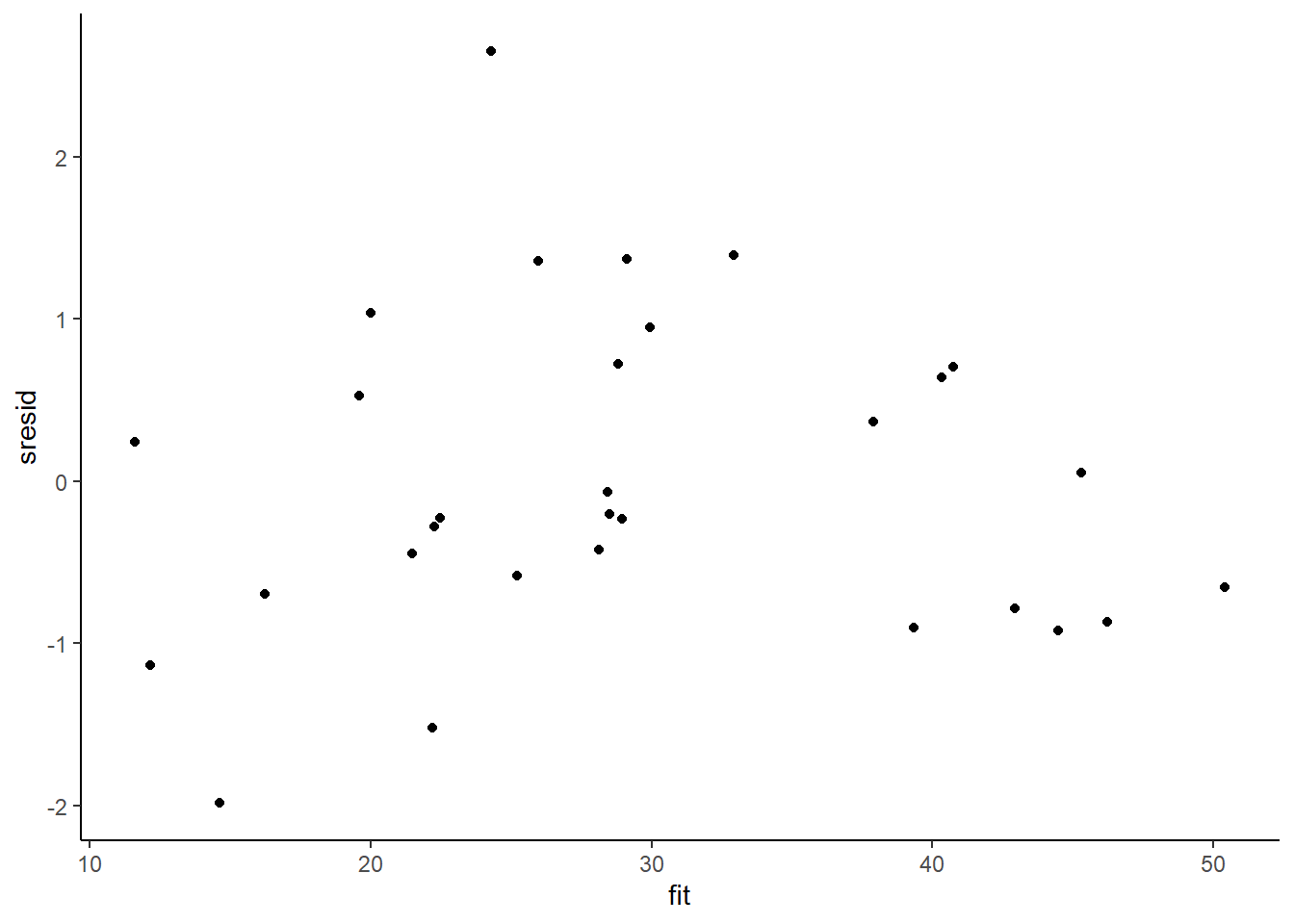
For this simple model, the studentized residuals yield the same pattern as the raw residuals (or the Pearson residuals for that matter). Lets see how well data simulated from the model reflects the raw data.
> mcmc = as.data.frame(data.rstan) %>% dplyr:::select(contains("beta"),
+ sigma) %>% as.matrix
> # generate a model matrix
> Xmat = model.matrix(~A + B, data)
> ## get median parameter estimates
> coefs = mcmc[, 1:4]
> fit = coefs %*% t(Xmat)
> ## draw samples from this model
> yRep = sapply(1:nrow(mcmc), function(i) rnorm(nrow(data), fit[i,
+ ], mcmc[i, "sigma"]))
> newdata = data.frame(A = data$A, B = data$B, yRep) %>% gather(key = Sample,
+ value = Value, -A, -B)
> ggplot(newdata) + geom_violin(aes(y = Value, x = A, fill = "Model"),
+ alpha = 0.5) + geom_violin(data = data, aes(y = Y, x = A,
+ fill = "Obs"), alpha = 0.5) + geom_point(data = data, aes(y = Y,
+ x = A), position = position_jitter(width = 0.1, height = 0),
+ color = "black") + theme_classic()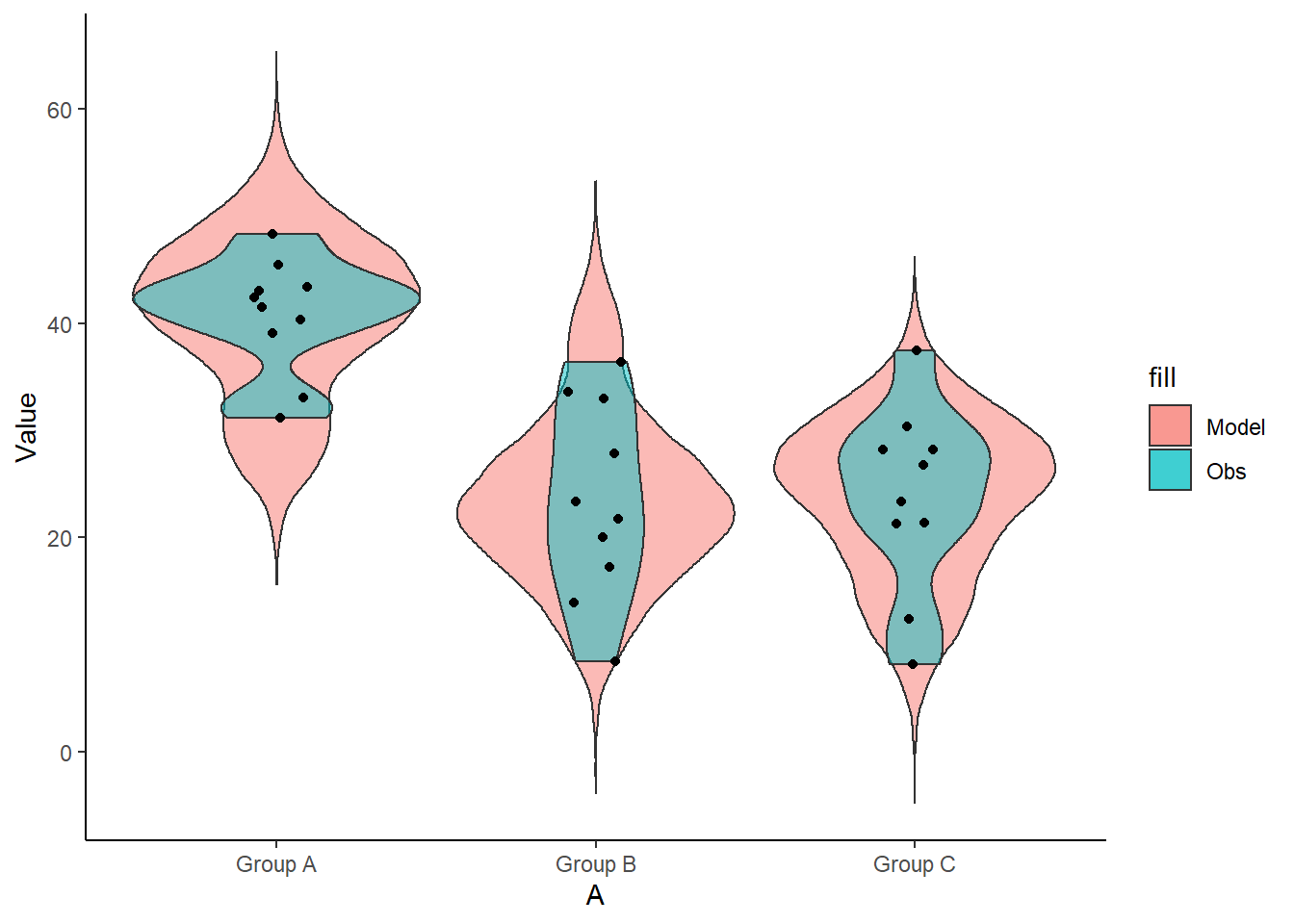
>
> ggplot(newdata) + geom_violin(aes(y = Value, x = B, fill = "Model",
+ group = B, color = A), alpha = 0.5) + geom_point(data = data,
+ aes(y = Y, x = B, group = B, color = A)) + theme_classic()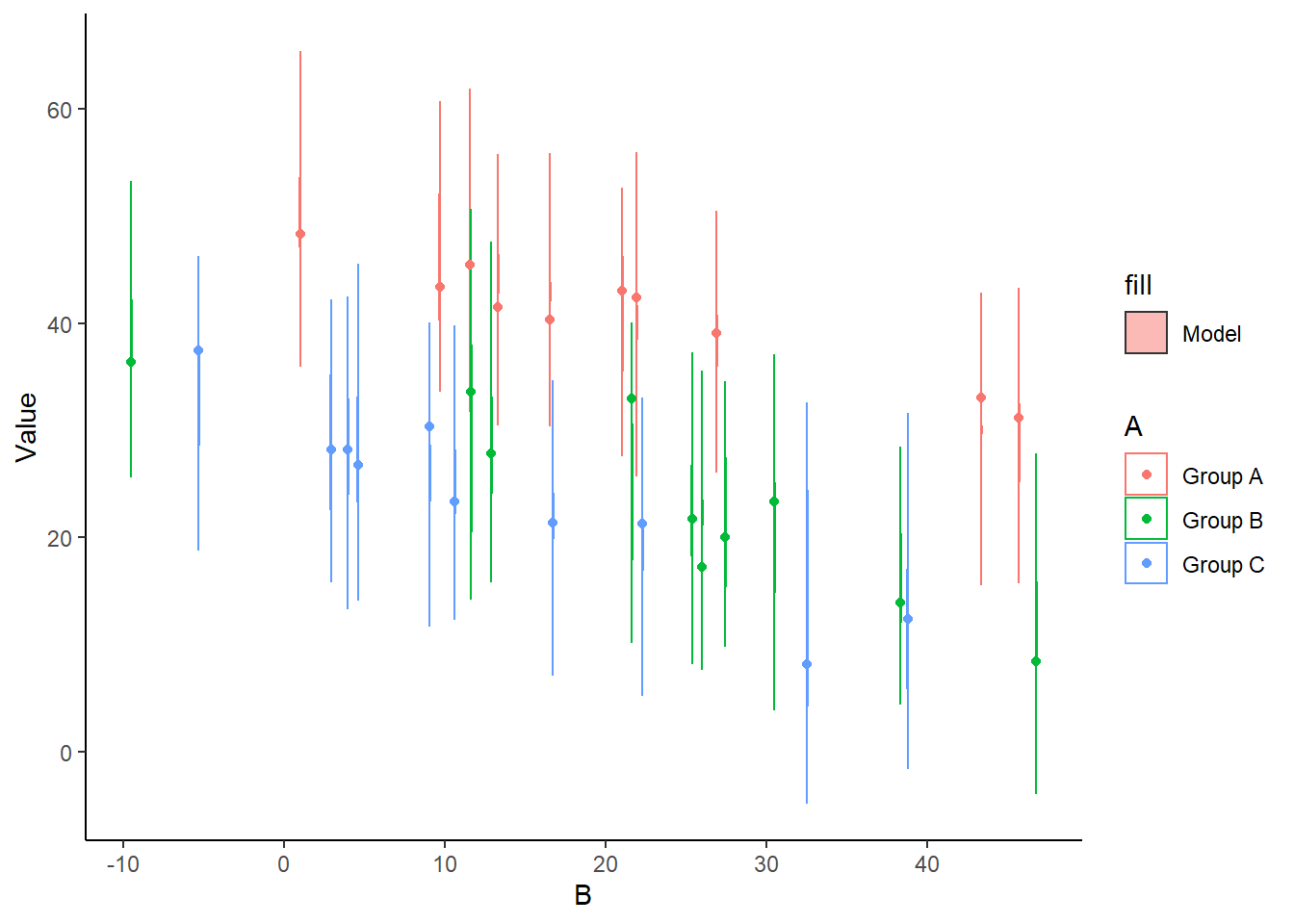
The predicted trends do encapsulate the actual data, suggesting that the model is a reasonable representation of the underlying processes. Note, these are prediction intervals rather than confidence intervals as we are seeking intervals within which we can predict individual observations rather than means. We can also explore the posteriors of each parameter.
> library(bayesplot)
> mcmc_intervals(as.matrix(data.rstan), regex_pars = "beta|sigma")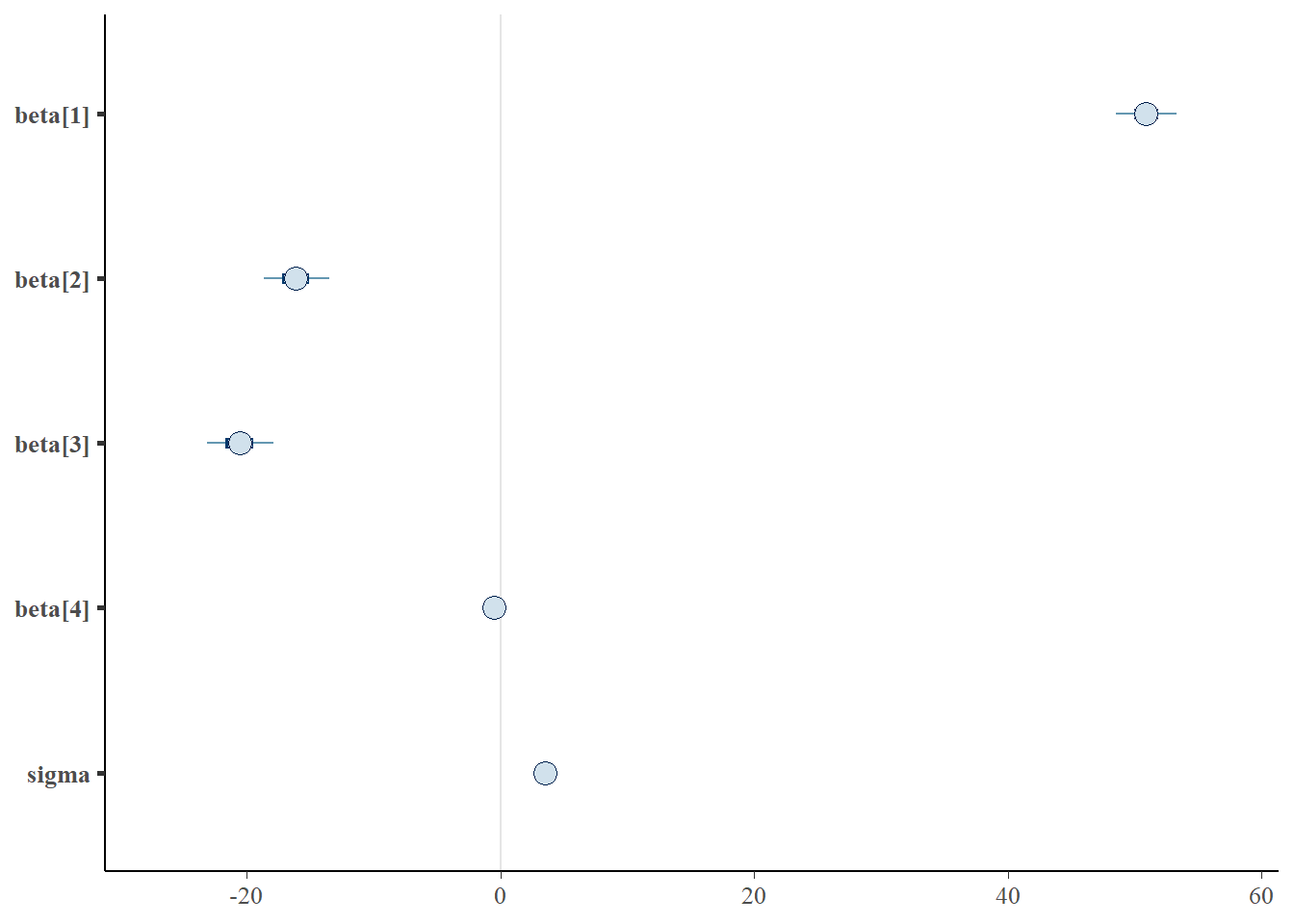
> mcmc_areas(as.matrix(data.rstan), regex_pars = "beta|sigma")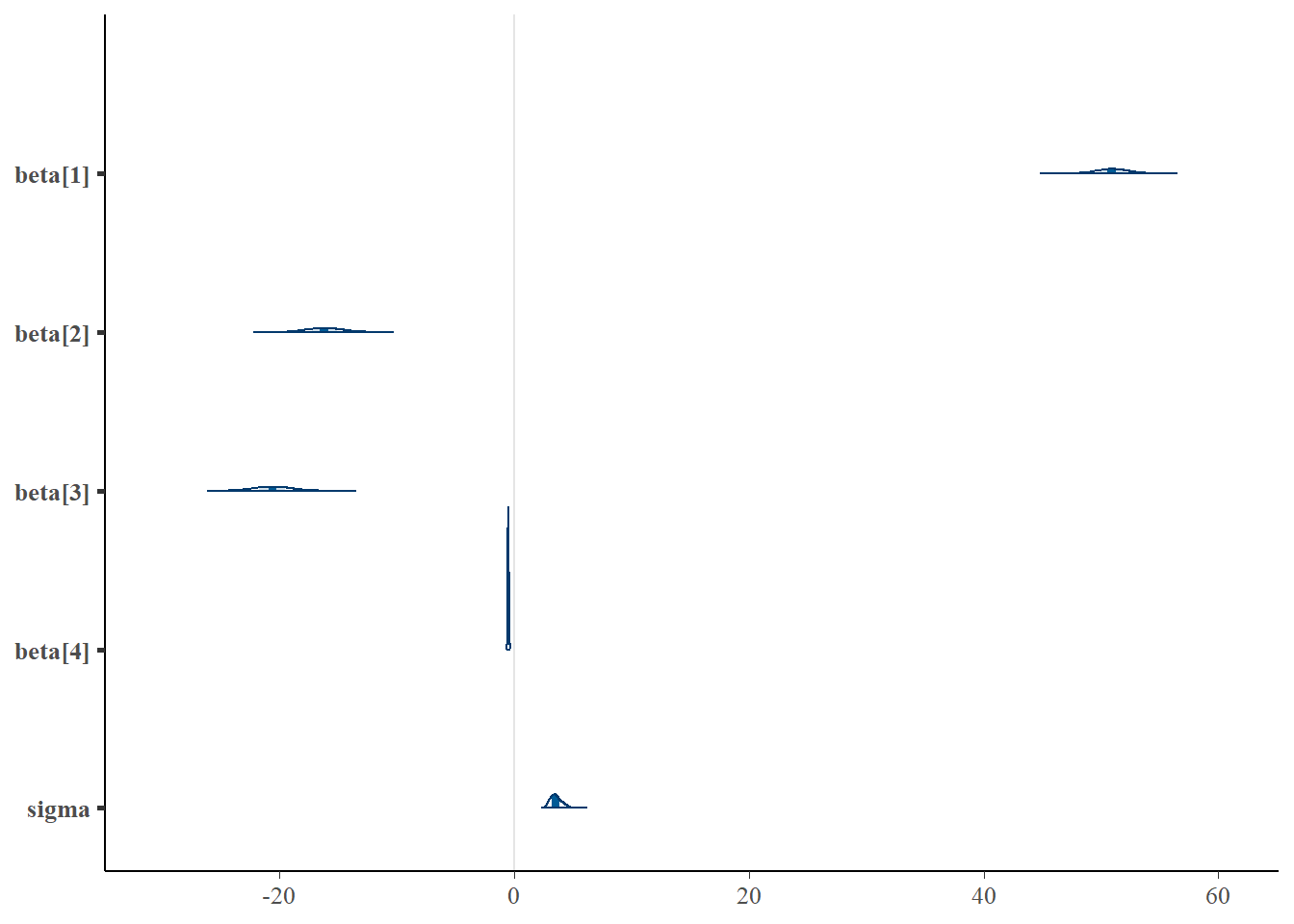
Parameter estimates
Although all parameters in a Bayesian analysis are considered random and are considered a distribution, rarely would it be useful to present tables of all the samples from each distribution. On the other hand, plots of the posterior distributions have some use. Nevertheless, most workers prefer to present simple statistical summaries of the posteriors. Popular choices include the median (or mean) and \(95\)% credibility intervals.
> mcmcpvalue <- function(samp) {
+ ## elementary version that creates an empirical p-value for the
+ ## hypothesis that the columns of samp have mean zero versus a general
+ ## multivariate distribution with elliptical contours.
+
+ ## differences from the mean standardized by the observed
+ ## variance-covariance factor
+
+ ## Note, I put in the bit for single terms
+ if (length(dim(samp)) == 0) {
+ std <- backsolve(chol(var(samp)), cbind(0, t(samp)) - mean(samp),
+ transpose = TRUE)
+ sqdist <- colSums(std * std)
+ sum(sqdist[-1] > sqdist[1])/length(samp)
+ } else {
+ std <- backsolve(chol(var(samp)), cbind(0, t(samp)) - colMeans(samp),
+ transpose = TRUE)
+ sqdist <- colSums(std * std)
+ sum(sqdist[-1] > sqdist[1])/nrow(samp)
+ }
+
+ }First, we look at the results from the additive model.
> print(data.rstan, pars = c("beta", "sigma"))
Inference for Stan model: ancovaModel.
2 chains, each with iter=1500; warmup=500; thin=1;
post-warmup draws per chain=1000, total post-warmup draws=2000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
beta[1] 50.93 0.05 1.44 48.08 49.99 50.92 51.88 53.88 978 1
beta[2] -16.14 0.05 1.58 -19.21 -17.21 -16.16 -15.08 -12.96 1216 1
beta[3] -20.57 0.05 1.62 -23.68 -21.69 -20.56 -19.47 -17.38 1268 1
beta[4] -0.48 0.00 0.04 -0.57 -0.51 -0.48 -0.45 -0.39 1189 1
sigma 3.58 0.02 0.52 2.76 3.22 3.51 3.88 4.69 1177 1
Samples were drawn using NUTS(diag_e) at Thu Jul 08 21:55:10 2021.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
>
> # OR
> library(broom)
> library(broom.mixed)
> tidyMCMC(data.rstan, conf.int = TRUE, conf.method = "HPDinterval", pars = c("beta", "sigma"))
# A tibble: 5 x 5
term estimate std.error conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl>
1 beta[1] 50.9 1.44 47.8 53.6
2 beta[2] -16.2 1.58 -19.0 -12.8
3 beta[3] -20.6 1.62 -23.5 -17.3
4 beta[4] -0.483 0.0446 -0.577 -0.405
5 sigma 3.51 0.516 2.68 4.58 Conclusions
The intercept of the first group (Group A) is \(51\).
The mean of the second group (Group B) is \(-16.3\) units greater than (A).
The mean of the third group (Group C) is \(-20.7\) units greater than (A).
A one unit increase in B in Group A is associated with a \(-0.484\) units increase in \(Y\).
The \(95\)% confidence interval for the effects of Group B, Group C and the partial slope associated with B do not overlapp with 0 implying a significant difference between group A and groups B, C and a significant negative relationship with B. While workers attempt to become comfortable with a new statistical framework, it is only natural that they like to evaluate and comprehend new structures and output alongside more familiar concepts. One way to facilitate this is via Bayesian p-values that are somewhat analogous to the frequentist p-values for investigating the hypothesis that a parameter is equal to zero.
> ## since values are less than zero
> mcmcpvalue(as.matrix(data.rstan)[, "beta[2]"]) # effect of (B-A = 0)
[1] 0
> mcmcpvalue(as.matrix(data.rstan)[, "beta[3]"]) # effect of (C-A = 0)
[1] 0
> mcmcpvalue(as.matrix(data.rstan)[, "beta[4]"]) # effect of (slope = 0)
[1] 0
> mcmcpvalue(as.matrix(data.rstan)[, 2:4]) # effect of (model)
[1] 0There is evidence that the reponse differs between the groups. There is evidence suggesting that the response of group D differs from that of group A. In a Bayesian context, we can compare models using the leave-one-out cross-validation statistics. Leave-one-out (LOO) cross-validation explores how well a series of models can predict withheld values Vehtari, Gelman, and Gabry (2017). The LOO Information Criterion (LOOIC) is analogous to the AIC except that the LOOIC takes priors into consideration, does not assume that the posterior distribution is drawn from a multivariate normal and integrates over parameter uncertainty so as to yield a distribution of looic rather than just a point estimate. The LOOIC does however assume that all observations are equally influential (it does not matter which observations are left out). This assumption can be examined via the Pareto \(k\) estimate (values greater than \(0.5\) or more conservatively \(0.75\) are considered overly influential). We can compute LOOIC if we store the loglikelihood from our Stan model, which can then be extracted to compute the information criterion using the package loo.
> library(loo)
> (full = loo(extract_log_lik(data.rstan)))
Computed from 2000 by 30 log-likelihood matrix
Estimate SE
elpd_loo -82.9 4.2
p_loo 4.6 1.3
looic 165.8 8.4
------
Monte Carlo SE of elpd_loo is 0.1.
Pareto k diagnostic values:
Count Pct. Min. n_eff
(-Inf, 0.5] (good) 29 96.7% 357
(0.5, 0.7] (ok) 1 3.3% 1070
(0.7, 1] (bad) 0 0.0% <NA>
(1, Inf) (very bad) 0 0.0% <NA>
All Pareto k estimates are ok (k < 0.7).
See help('pareto-k-diagnostic') for details.
>
> # now fit a model without main factor
> modelString2 = "
+ data {
+ int<lower=1> n;
+ int<lower=1> nX;
+ vector [n] y;
+ matrix [n,nX] X;
+ }
+ parameters {
+ vector[nX] beta;
+ real<lower=0> sigma;
+ }
+ transformed parameters {
+ vector[n] mu;
+
+ mu = X*beta;
+ }
+ model {
+ // Likelihood
+ y~normal(mu,sigma);
+
+ // Priors
+ beta ~ normal(0,1000);
+ sigma~cauchy(0,5);
+ }
+ generated quantities {
+ vector[n] log_lik;
+
+ for (i in 1:n) {
+ log_lik[i] = normal_lpdf(y[i] | mu[i], sigma);
+ }
+ }
+
+ "
>
> ## write the model to a stan file
> writeLines(modelString2, con = "ancovaModel2.stan")
>
> Xmat <- model.matrix(~1, data)
> data.list <- with(data, list(y = Y, X = Xmat, n = nrow(data), nX = ncol(Xmat)))
> data.rstan.red <- stan(data = data.list, file = "ancovaModel2.stan", chains = nChains,
+ iter = nIter, warmup = burnInSteps, thin = thinSteps)
SAMPLING FOR MODEL 'ancovaModel2' NOW (CHAIN 1).
Chain 1:
Chain 1: Gradient evaluation took 0 seconds
Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Chain 1: Adjust your expectations accordingly!
Chain 1:
Chain 1:
Chain 1: Iteration: 1 / 1500 [ 0%] (Warmup)
Chain 1: Iteration: 150 / 1500 [ 10%] (Warmup)
Chain 1: Iteration: 300 / 1500 [ 20%] (Warmup)
Chain 1: Iteration: 450 / 1500 [ 30%] (Warmup)
Chain 1: Iteration: 501 / 1500 [ 33%] (Sampling)
Chain 1: Iteration: 650 / 1500 [ 43%] (Sampling)
Chain 1: Iteration: 800 / 1500 [ 53%] (Sampling)
Chain 1: Iteration: 950 / 1500 [ 63%] (Sampling)
Chain 1: Iteration: 1100 / 1500 [ 73%] (Sampling)
Chain 1: Iteration: 1250 / 1500 [ 83%] (Sampling)
Chain 1: Iteration: 1400 / 1500 [ 93%] (Sampling)
Chain 1: Iteration: 1500 / 1500 [100%] (Sampling)
Chain 1:
Chain 1: Elapsed Time: 0.017 seconds (Warm-up)
Chain 1: 0.028 seconds (Sampling)
Chain 1: 0.045 seconds (Total)
Chain 1:
SAMPLING FOR MODEL 'ancovaModel2' NOW (CHAIN 2).
Chain 2:
Chain 2: Gradient evaluation took 0 seconds
Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Chain 2: Adjust your expectations accordingly!
Chain 2:
Chain 2:
Chain 2: Iteration: 1 / 1500 [ 0%] (Warmup)
Chain 2: Iteration: 150 / 1500 [ 10%] (Warmup)
Chain 2: Iteration: 300 / 1500 [ 20%] (Warmup)
Chain 2: Iteration: 450 / 1500 [ 30%] (Warmup)
Chain 2: Iteration: 501 / 1500 [ 33%] (Sampling)
Chain 2: Iteration: 650 / 1500 [ 43%] (Sampling)
Chain 2: Iteration: 800 / 1500 [ 53%] (Sampling)
Chain 2: Iteration: 950 / 1500 [ 63%] (Sampling)
Chain 2: Iteration: 1100 / 1500 [ 73%] (Sampling)
Chain 2: Iteration: 1250 / 1500 [ 83%] (Sampling)
Chain 2: Iteration: 1400 / 1500 [ 93%] (Sampling)
Chain 2: Iteration: 1500 / 1500 [100%] (Sampling)
Chain 2:
Chain 2: Elapsed Time: 0.021 seconds (Warm-up)
Chain 2: 0.022 seconds (Sampling)
Chain 2: 0.043 seconds (Total)
Chain 2:
>
> (reduced = loo(extract_log_lik(data.rstan.red)))
Computed from 2000 by 30 log-likelihood matrix
Estimate SE
elpd_loo -116.3 3.1
p_loo 1.6 0.3
looic 232.6 6.3
------
Monte Carlo SE of elpd_loo is 0.0.
All Pareto k estimates are good (k < 0.5).
See help('pareto-k-diagnostic') for details.
>
> par(mfrow = 1:2, mar = c(5, 3.8, 1, 0) + 0.1, las = 3)
> plot(full, label_points = TRUE)
> plot(reduced, label_points = TRUE)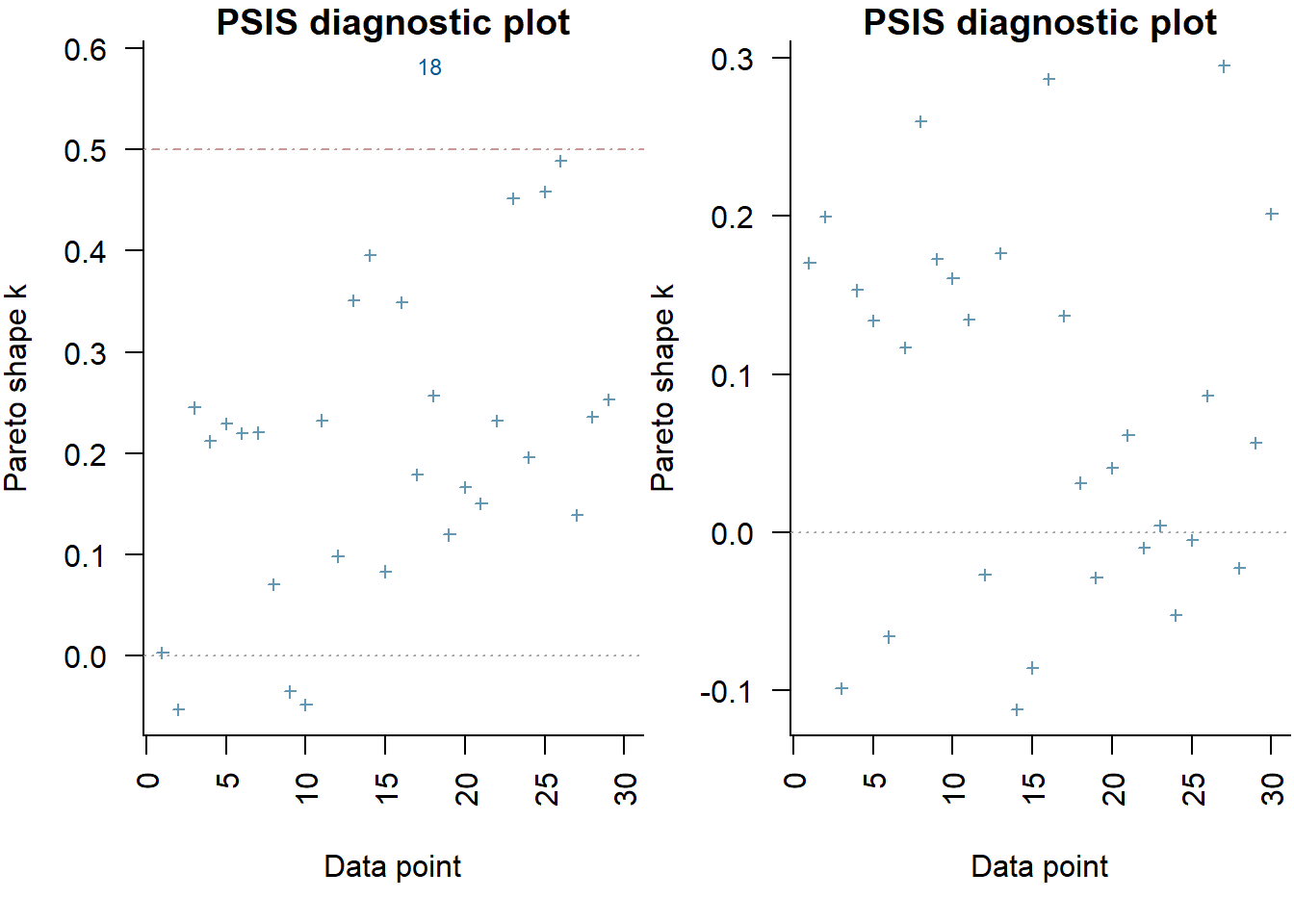
The expected out-of-sample predictive accuracy is substantially lower for the model that includes \(x\). This might be used to suggest that the inferential evidence for a general effect of \(x\) on \(y\).
Graphical summaries
A nice graphic is often a great accompaniment to a statistical analysis. Although there are no fixed assumptions associated with graphing (in contrast to statistical analyses), we often want the graphical summaries to reflect the associated statistical analyses. After all, the sample is just one perspective on the population(s). What we are more interested in is being able to estimate and depict likely population parameters/trends. Thus, whilst we could easily provide a plot displaying the raw data along with simple measures of location and spread, arguably, we should use estimates that reflect the fitted model. In this case, it would be appropriate to plot the credibility interval associated with each group.
> mcmc = as.matrix(data.rstan)
> ## Calculate the fitted values
> newdata = expand.grid(A = levels(data$A), B = seq(min(data$B), max(data$B),
+ len = 100))
> Xmat = model.matrix(~A + B, newdata)
> coefs = mcmc[, c("beta[1]", "beta[2]", "beta[3]", "beta[4]")]
> fit = coefs %*% t(Xmat)
> newdata = newdata %>% cbind(tidyMCMC(fit, conf.int = TRUE, conf.method = "HPDinterval"))
>
> ggplot(newdata, aes(y = estimate, x = B, fill = A)) + geom_ribbon(aes(ymin = conf.low,
+ ymax = conf.high), alpha = 0.2) + geom_line() + scale_y_continuous("Y") +
+ scale_x_continuous("B") + theme_classic()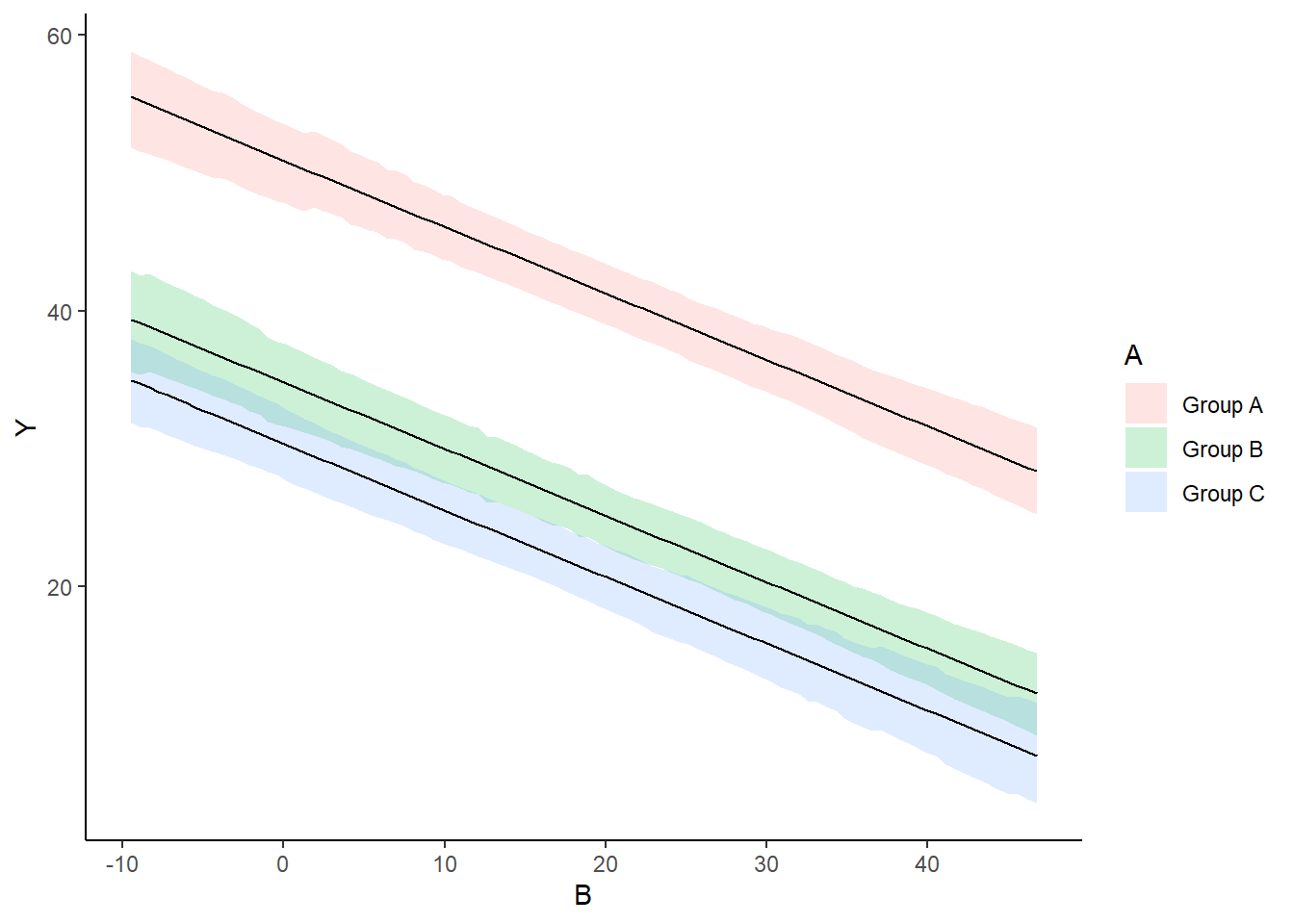
As this is simple single factor ANOVA, we can simple add the raw data to this figure. For more complex designs with additional predictors, it is necessary to plot partial residuals.
> ## Calculate partial residuals fitted values
> fdata = rdata = data
> fMat = rMat = model.matrix(~A + B, fdata)
> fit = as.vector(apply(coefs, 2, median) %*% t(fMat))
> resid = as.vector(data$Y - apply(coefs, 2, median) %*% t(rMat))
> rdata = rdata %>% mutate(partial.resid = resid + fit)
>
> ggplot(newdata, aes(y = estimate, x = B, fill = A)) + geom_point(data = rdata,
+ aes(y = partial.resid, x = B, color = A)) + geom_ribbon(aes(ymin = conf.low,
+ ymax = conf.high), alpha = 0.2) + geom_line() + scale_y_continuous("Y") +
+ scale_x_continuous("B") + theme_classic()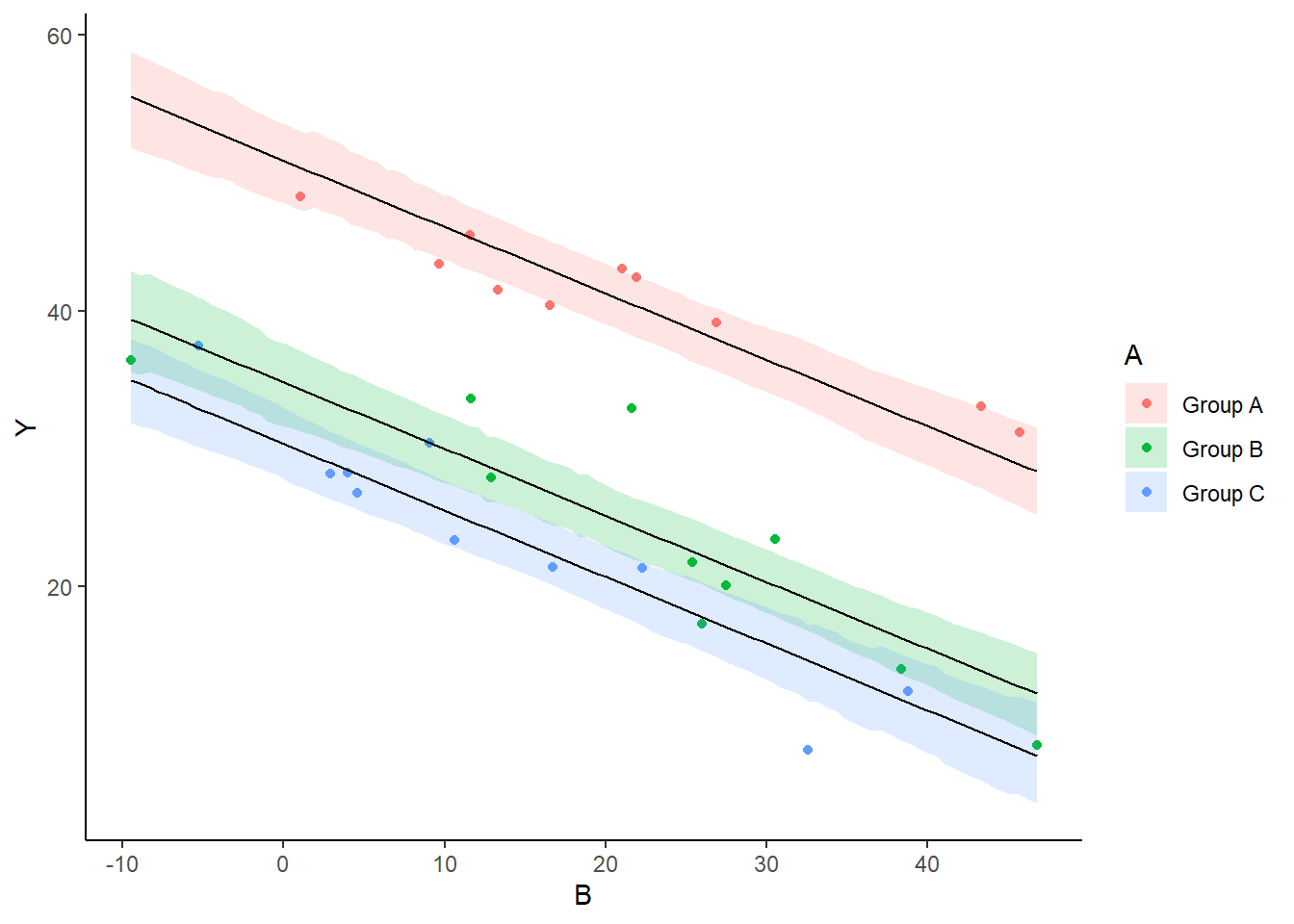
Posteriors
In frequentist statistics, when we have more than two groups, we are typically not only interested in whether there is evidence for an overall “effect” of a factor - we are also interested in how various groups compare to one another. To explore these trends, we either compare each group to each other in a pairwise manner (controlling for family-wise Type I error rates) or we explore an independent subset of the possible comparisons. Although these alternate approaches can adequately address a specific research agenda, often they impose severe limitations and compromises on the scope and breadth of questions that can be asked of your data. The reason for these limitations is that in a frequentist framework, any single hypothesis carries with it a (nominally) \(5\)% chance of a false rejection (since it is based on long-run frequency). Thus, performing multiple tests are likely to compound this error rate. The point is, that each comparison is compared to its own probability distribution (and each carries a \(5\)% error rate). By contrast, in Bayesian statistics, all comparisons (contrasts) are drawn from the one (hopefully stable and convergent) posterior distribution and this posterior is invariant to the type and number of comparisons drawn. Hence, the theory clearly indicates that having generated our posterior distribution, we can then query this distribution in any way that we wish thereby allowing us to explore all of our research questions simultaneously.
Bayesian “contrasts” can be performed either:
within the Bayesian sampling model or
construct them from the returned MCMC samples (they are drawn from the posteriors)
Only the latter will be demonstrated as it provides a consistent approach across all routines. In order to allow direct comparison to the frequentist equivalents, I will explore the same set of planned and Tukey’s test comparisons described here. For the “planned comparison” we defined two contrasts: 1) group B vs group C; and 2) group A vs the average of groups B and C. Of course each of these could be explored at multiple values of B, however, since we fit an additive model (which assumes that the slopes are homogeneous), the contrasts will be constant throughout the domain of B.
Lets start by comparing each group to each other group in a pairwise manner. Arguably the most elegant way to do this is to generate a Tukey’s contrast matrix. This is a model matrix specific to comparing each group to each other group. Again, since the lines are parallel, it does not really matter what level of B we estimate these efffects at - so lets use the mean B.
> mcmc = data.rstan
> coefs <- as.matrix(mcmc)[, 1:4]
> newdata <- data.frame(A = levels(data$A), B = mean(data$B))
> # A Tukeys contrast matrix
> library(multcomp)
> tuk.mat <- contrMat(n = table(newdata$A), type = "Tukey")
> Xmat <- model.matrix(~A + B, data = newdata)
> pairwise.mat <- tuk.mat %*% Xmat
> pairwise.mat
(Intercept) AGroup B AGroup C B
Group B - Group A 0 1 0 0
Group C - Group A 0 0 1 0
Group C - Group B 0 -1 1 0
>
> mcmc_areas(coefs %*% t(pairwise.mat))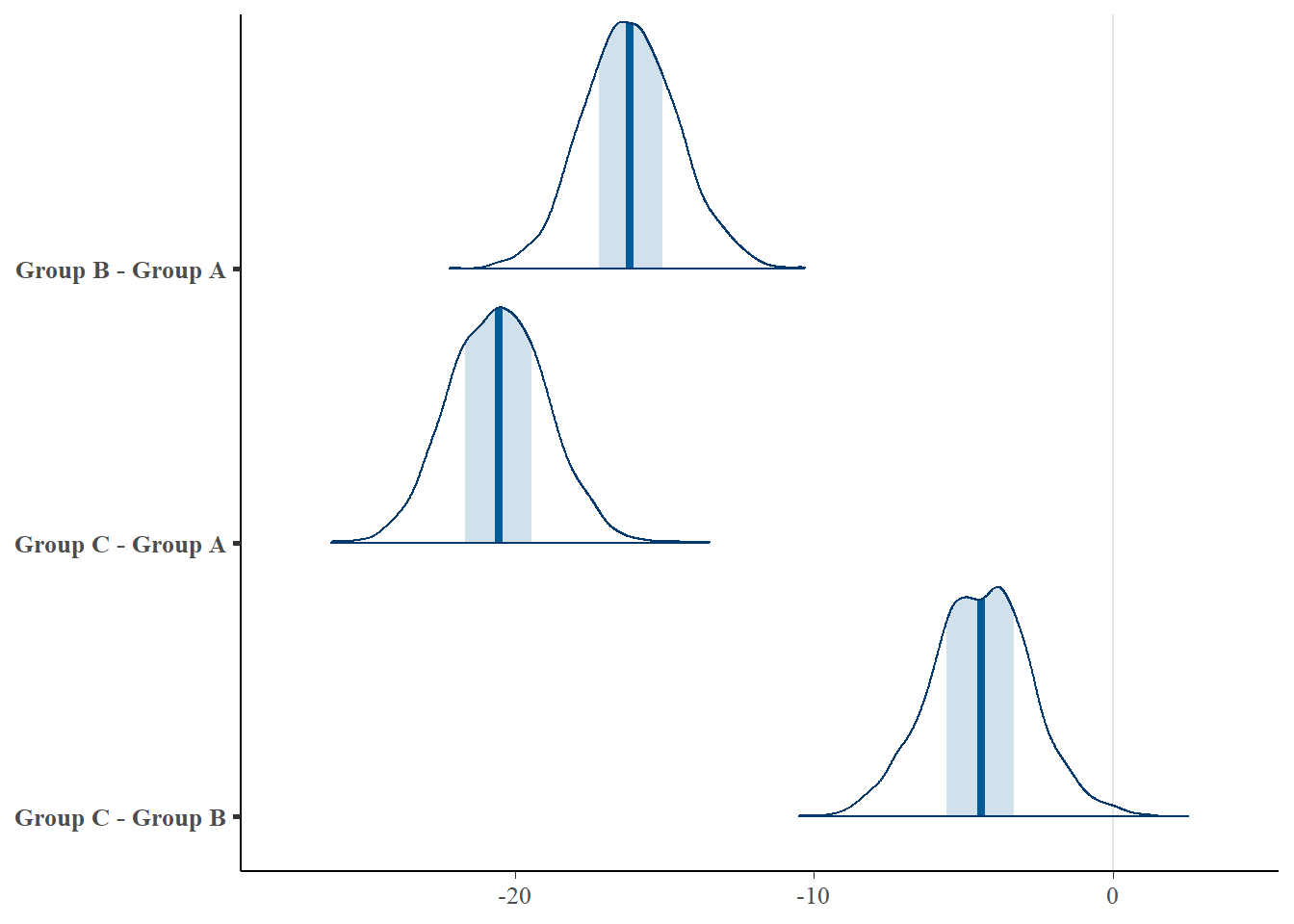
>
> (comps = tidyMCMC(coefs %*% t(pairwise.mat), conf.int = TRUE, conf.method = "HPDinterval"))
# A tibble: 3 x 5
term estimate std.error conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl>
1 Group B - Group A -16.2 1.58 -19.0 -12.8
2 Group C - Group A -20.6 1.62 -23.5 -17.3
3 Group C - Group B -4.41 1.69 -8.03 -1.32
>
> ggplot(comps, aes(y = estimate, x = term)) + geom_pointrange(aes(ymin = conf.low,
+ ymax = conf.high)) + geom_hline(yintercept = 0, linetype = "dashed") +
+ scale_y_continuous("Effect size") + scale_x_discrete("") + coord_flip() +
+ theme_classic()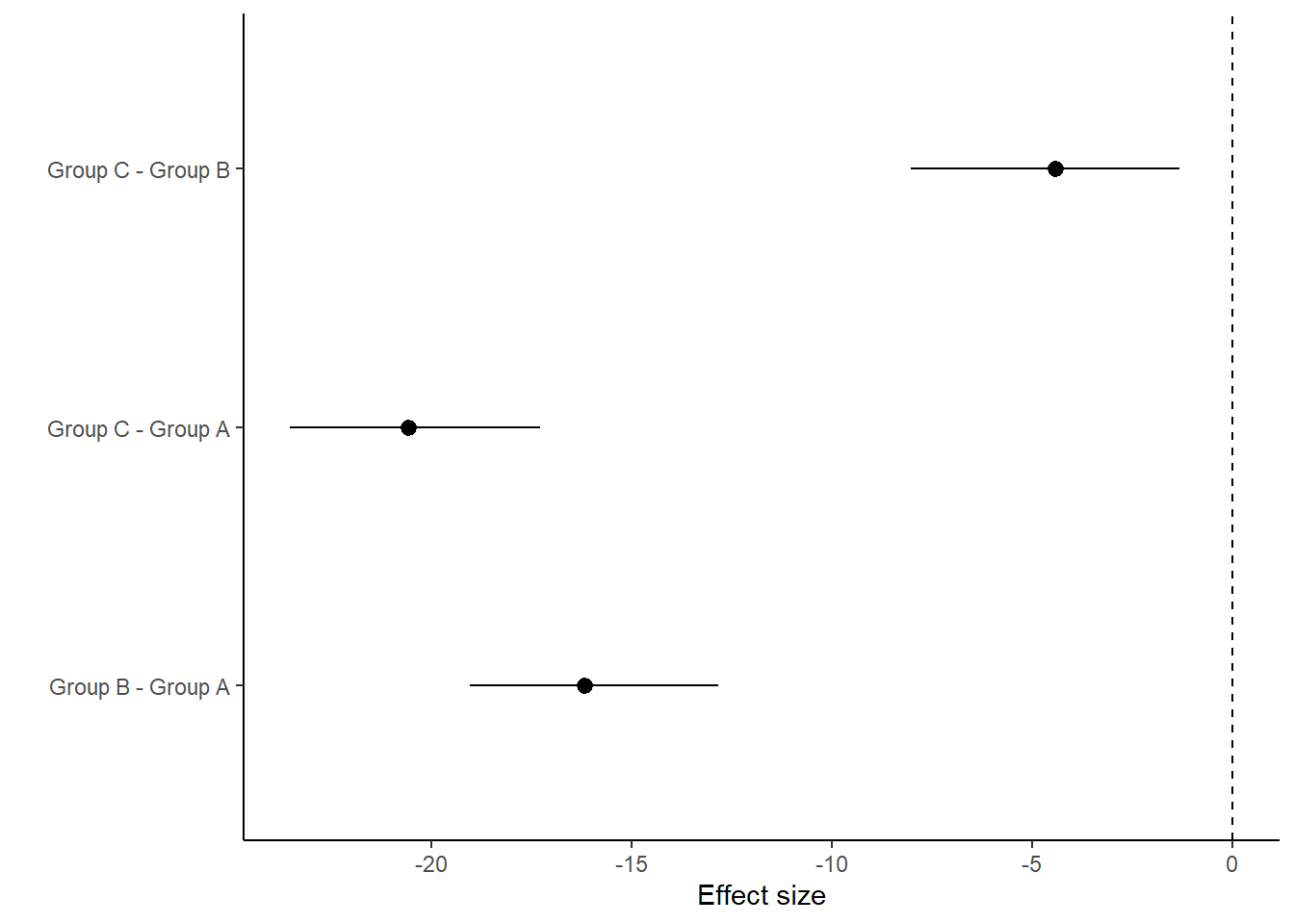
With a couple of modifications, we could also express this as percentage changes. A percentage change represents the change (difference between groups) divided by one of the groups (determined by which group you want to express the percentage change to). Hence, we generate an additional mcmc matrix that represents the cell means for the divisor group (group we want to express change relative to). Since the tuk.mat defines comparisons as \(-1\) and \(1\) pairs, if we simply replace all the \(-1\) with \(0\), the eventual matrix multiplication will result in estimates of the divisor cell means instread of the difference. We can then divide the original mcmc matrix above with this new divisor mcmc matrix to yeild a mcmc matrix of percentage change.
> # Modify the tuk.mat to replace -1 with 0. This will allow us to get a
> # mcmc matrix of ..
> tuk.mat[tuk.mat == -1] = 0
> comp.mat <- tuk.mat %*% Xmat
> comp.mat
(Intercept) AGroup B AGroup C B
Group B - Group A 1 1 0 19.29344
Group C - Group A 1 0 1 19.29344
Group C - Group B 1 0 1 19.29344
>
> comp.mcmc = 100 * (coefs %*% t(pairwise.mat))/coefs %*% t(comp.mat)
> (comps = tidyMCMC(comp.mcmc, conf.int = TRUE, conf.method = "HPDinterval"))
# A tibble: 3 x 5
term estimate std.error conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl>
1 Group B - Group A -63.5 8.51 -81.6 -48.3
2 Group C - Group A -97.7 12.3 -123. -75.2
3 Group C - Group B -20.9 9.04 -39.3 -4.12
>
> ggplot(comps, aes(y = estimate, x = term)) + geom_pointrange(aes(ymin = conf.low,
+ ymax = conf.high)) + geom_hline(yintercept = 0, linetype = "dashed") +
+ scale_y_continuous("Effect size (%)") + scale_x_discrete("") + coord_flip() +
+ theme_classic()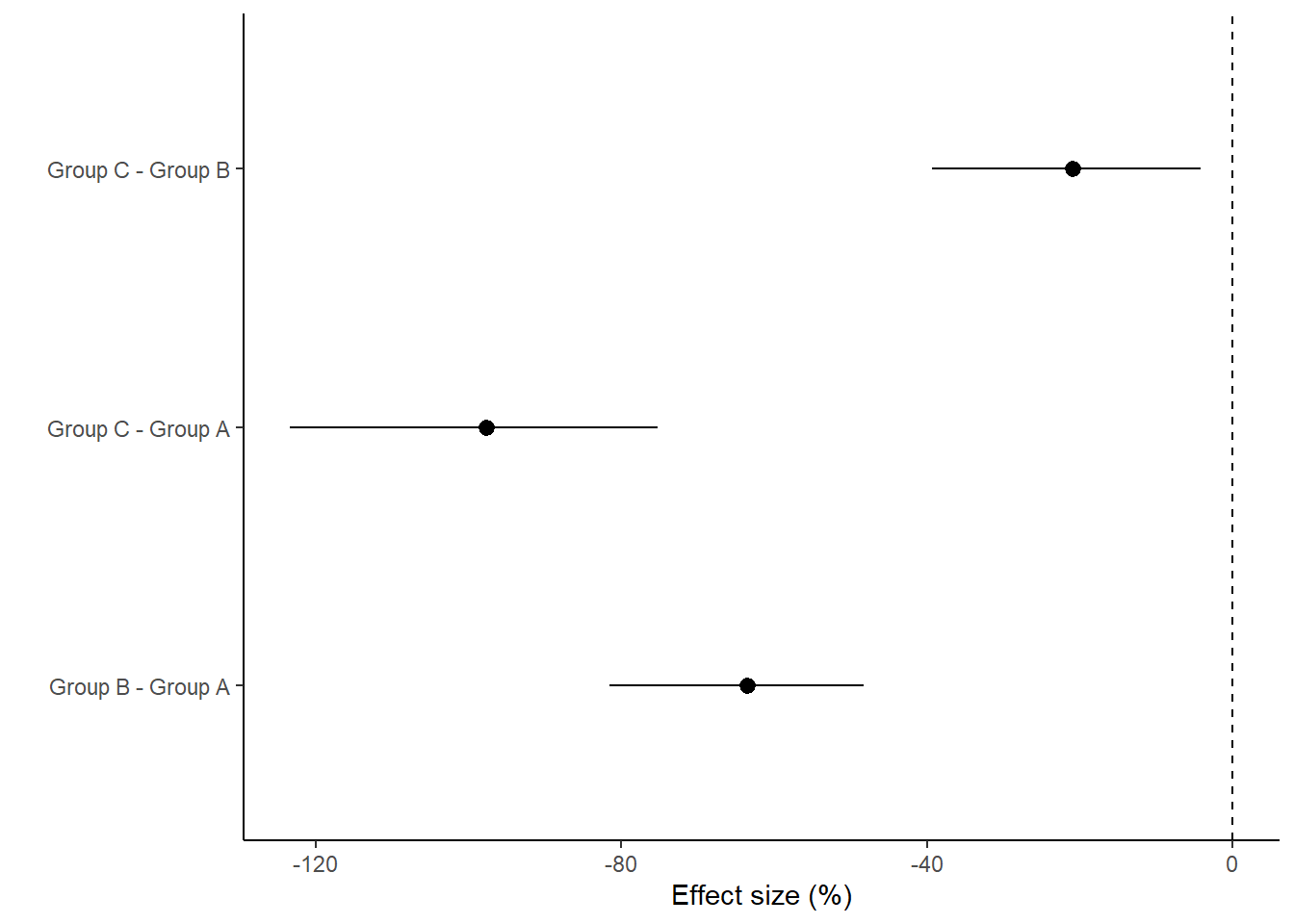
And now for the specific planned comparisons (Group B vs Group C as well as Group A vs the average of Groups B and C). This is achieved by generating our own contrast matrix (defining the contributions of each group to each contrast).
> c.mat = rbind(c(0, 1, -1), c(1/2, -1/3, -1/3))
> c.mat
[,1] [,2] [,3]
[1,] 0.0 1.0000000 -1.0000000
[2,] 0.5 -0.3333333 -0.3333333
>
> mcmc = data.rstan
> coefs <- as.matrix(mcmc)[, 1:4]
> newdata <- data.frame(A = levels(data$A), B = mean(data$B))
> Xmat <- model.matrix(~A + B, data = newdata)
> c.mat = c.mat %*% Xmat
> c.mat
(Intercept) AGroup B AGroup C B
[1,] 0.0000000 1.0000000 -1.0000000 0.000000
[2,] -0.1666667 -0.3333333 -0.3333333 -3.215574
>
> (comps = tidyMCMC(as.mcmc(coefs %*% t(c.mat)), conf.int = TRUE, conf.method = "HPDinterval"))
# A tibble: 2 x 5
term estimate std.error conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl>
1 var1 4.41 1.69 1.32 8.03
2 var2 5.32 0.761 3.80 6.76Finite population standard deviations
Variance components, the amount of added variance attributed to each influence, are traditionally estimated for so called random effects. These are the effects for which the levels employed in the design are randomly selected to represent a broader range of possible levels. For such effects, effect sizes (differences between each level and a reference level) are of little value. Instead, the “importance” of the variables are measured in units of variance components. On the other hand, regular variance components for fixed factors (those whose measured levels represent the only levels of interest) are not logical - since variance components estimate variance as if the levels are randomly selected from a larger population. Nevertheless, in order to compare and contrast the scale of variability of both fixed and random factors, it is necessary to measure both on the same scale (sample or population based variance).
Finite-population variance components assume that the levels of all factors (fixed and random) in the design are all the possible levels available (Gelman and others (2005)). In other words, they are assumed to represent finite populations of levels. Sample (rather than population) statistics are then used to calculate these finite-population variances (or standard deviations). Since standard deviation (and variance) are bound at zero, standard deviation posteriors are typically non-normal. Consequently, medians and HPD intervals are more robust estimates.
parameters
iterations beta[1] beta[2] beta[3] beta[4] sigma log_lik[1]
[1,] 50.46775 -17.37306 -17.30715 -0.4655002 2.944843 -2.009059
[2,] 49.65259 -14.90921 -18.90192 -0.4913259 3.086606 -2.169242
[3,] 53.55891 -15.89543 -20.09903 -0.5952382 3.755696 -2.290681
[4,] 49.65602 -16.57949 -21.03937 -0.3950509 3.894001 -2.283995
[5,] 51.01692 -16.01156 -18.36863 -0.5179239 3.977769 -2.306831
[6,] 48.35451 -13.18800 -18.60008 -0.4479684 3.249965 -2.354092
parameters
iterations log_lik[2] log_lik[3] log_lik[4] log_lik[5] log_lik[6] log_lik[7]
[1,] -2.328758 -2.446242 -2.323167 -2.267657 -2.228600 -2.077259
[2,] -2.115302 -3.215542 -2.776248 -2.703836 -2.882209 -2.421637
[3,] -2.636681 -3.246268 -2.385709 -2.372050 -3.071503 -2.329105
[4,] -2.526942 -2.288018 -2.373606 -2.345312 -2.284029 -2.278591
[5,] -2.435488 -2.942461 -2.570193 -2.540310 -2.766482 -2.429476
[6,] -2.112877 -2.908105 -2.899269 -2.812896 -2.615335 -2.470436
parameters
iterations log_lik[8] log_lik[9] log_lik[10] log_lik[11] log_lik[12]
[1,] -2.165526 -2.371346 -2.445624 -2.093296 -2.011585
[2,] -2.084638 -2.160299 -2.184462 -2.242899 -2.060503
[3,] -3.011263 -2.920506 -2.851811 -2.269092 -2.265269
[4,] -2.308761 -2.470328 -2.557522 -2.796323 -2.334425
[5,] -2.451911 -2.510345 -2.518966 -2.343551 -2.300056
[6,] -2.104997 -2.114514 -2.136221 -2.863835 -2.296478
parameters
iterations log_lik[13] log_lik[14] log_lik[15] log_lik[16] log_lik[17]
[1,] -2.811116 -7.669161 -4.018226 -2.471142 -2.003529
[2,] -3.220185 -6.135700 -3.142289 -2.618094 -2.124097
[3,] -3.109787 -4.601503 -2.532605 -2.307606 -2.300804
[4,] -3.300460 -4.610090 -3.140920 -3.521818 -2.437595
[5,] -2.883986 -4.940523 -2.973752 -2.469555 -2.317491
[6,] -3.965089 -4.735787 -2.725364 -3.664901 -2.477743
parameters
iterations log_lik[18] log_lik[19] log_lik[20] log_lik[21] log_lik[22]
[1,] -2.069846 -3.165624 -2.033349 -2.547930 -2.928636
[2,] -2.519155 -2.740516 -2.061508 -2.063231 -2.118279
[3,] -3.934659 -2.778362 -2.401861 -2.533822 -2.405184
[4,] -2.284225 -2.463007 -2.278845 -2.324116 -2.292314
[5,] -2.690579 -2.853792 -2.306406 -2.476331 -2.517584
[6,] -2.527565 -2.266921 -2.207848 -2.100559 -2.136149
parameters
iterations log_lik[23] log_lik[24] log_lik[25] log_lik[26] log_lik[27]
[1,] -3.045621 -2.120944 -3.382752 -2.190632 -7.593861
[2,] -2.203382 -2.927548 -2.303427 -2.926577 -4.331998
[3,] -2.798604 -2.434877 -2.759453 -2.266997 -3.486609
[4,] -2.278432 -3.225561 -2.318532 -3.776541 -4.183575
[5,] -2.688233 -2.488099 -2.763132 -2.433443 -4.139922
[6,] -2.138992 -3.143980 -2.231047 -3.438489 -4.427513
parameters
iterations log_lik[28] log_lik[29] log_lik[30] lp__
[1,] -2.124683 -2.754458 -2.417848 -55.92449
[2,] -2.165574 -2.113530 -2.072978 -50.58479
[3,] -2.286477 -2.686234 -2.389757 -53.39737
[4,] -2.352213 -2.295369 -2.304220 -51.94134
[5,] -2.300987 -2.575405 -2.300357 -51.93697
[6,] -2.209663 -2.100906 -2.097627 -52.03372
# A tibble: 3 x 5
term estimate std.error conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl>
1 sd.A 3.12 1.18 0.647 5.35
2 sd.B 7.11 0.656 5.96 8.49
3 sd.resid 3.40 0.160 3.26 3.75
# A tibble: 3 x 5
term estimate std.error conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl>
1 sd.A 22.9 6.68 8.08 34.0
2 sd.B 52.2 4.62 43.4 61.8
3 sd.resid 24.9 3.12 21.0 31.8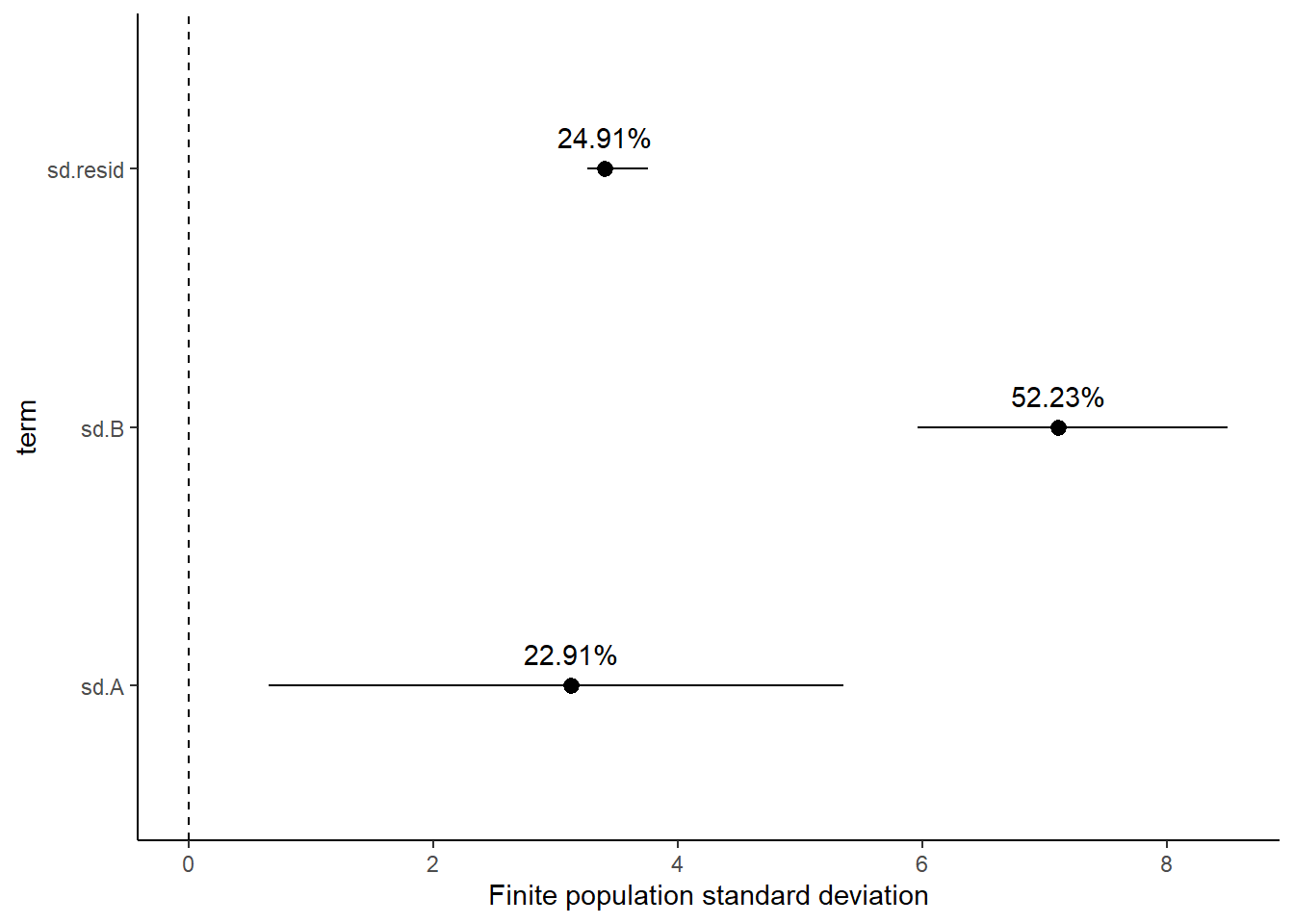
Approximately \(22.86\)% of the total finite population standard deviation is due to \(x\).
R squared
In a frequentist context, the \(R^2\) value is seen as a useful indicator of goodness of fit. Whilst it has long been acknowledged that this measure is not appropriate for comparing models (for such purposes information criterion such as AIC are more appropriate), it is nevertheless useful for estimating the amount (percent) of variance explained by the model. In a frequentist context, \(R^2\) is calculated as the variance in predicted values divided by the variance in the observed (response) values. Unfortunately, this classical formulation does not translate simply into a Bayesian context since the equivalently calculated numerator can be larger than the an equivalently calculated denominator - thereby resulting in an \(R^2\) greater than \(100\)%. Gelman et al. (2019) proposed an alternative formulation in which the denominator comprises the sum of the explained variance and the variance of the residuals.
So in the standard regression model notation of:
\[ y_i \sim \text{Normal}(\boldsymbol X \boldsymbol \beta, \sigma),\]
the \(R^2\) could be formulated as
\[ R^2 = \frac{\sigma^2_f}{\sigma^2_f + \sigma^2_e},\]
where \(\sigma^2_f=\text{var}(\boldsymbol X \boldsymbol \beta)\), and for normal models \(\sigma^2_e=\text{var}(y-\boldsymbol X \boldsymbol \beta)\)
> mcmc <- as.matrix(data.rstan)
> Xmat = model.matrix(~A + B, data)
> wch = grep("beta", colnames(mcmc))
> coefs = mcmc[, wch]
> fit = coefs %*% t(Xmat)
> resid = sweep(fit, 2, data$Y, "-")
> var_f = apply(fit, 1, var)
> var_e = apply(resid, 1, var)
> R2 = var_f/(var_f + var_e)
> tidyMCMC(as.mcmc(R2), conf.int = TRUE, conf.method = "HPDinterval")
# A tibble: 1 x 5
term estimate std.error conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl>
1 var1 0.909 0.0145 0.876 0.921
>
> # for comparison with frequentist
> summary(lm(Y ~ A + B, data))
Call:
lm(formula = Y ~ A + B, data = data)
Residuals:
Min 1Q Median 3Q Max
-6.4381 -2.2244 -0.6829 2.1732 8.6607
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 51.00608 1.44814 35.22 < 2e-16 ***
AGroup B -16.25472 1.54125 -10.55 6.92e-11 ***
AGroup C -20.65596 1.57544 -13.11 5.74e-13 ***
B -0.48399 0.04526 -10.69 5.14e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.44 on 26 degrees of freedom
Multiple R-squared: 0.9149, Adjusted R-squared: 0.9051
F-statistic: 93.22 on 3 and 26 DF, p-value: 4.901e-14Dealing with heterogeneous slopes
Generate the data with heterogeneous slope effects.
> set.seed(123)
> n <- 10
> p <- 3
> A.eff <- c(40, -15, -20)
> beta <- c(-0.45, -0.1, 0.5)
> sigma <- 4
> B <- rnorm(n * p, 0, 15)
> A <- gl(p, n, lab = paste("Group", LETTERS[1:3]))
> mm <- model.matrix(~A * B)
> data1 <- data.frame(A = A, B = B, Y = as.numeric(c(A.eff, beta) %*% t(mm)) + rnorm(n * p, 0, 4))
> data1$B <- data1$B + 20
> head(data1)
A B Y
1 Group A 11.59287 45.48907
2 Group A 16.54734 40.37341
3 Group A 43.38062 33.05922
4 Group A 21.05763 43.03660
5 Group A 21.93932 42.41363
6 Group A 45.72597 31.17787Exploratory data analysis
> scatterplot(Y ~ B | A, data = data1)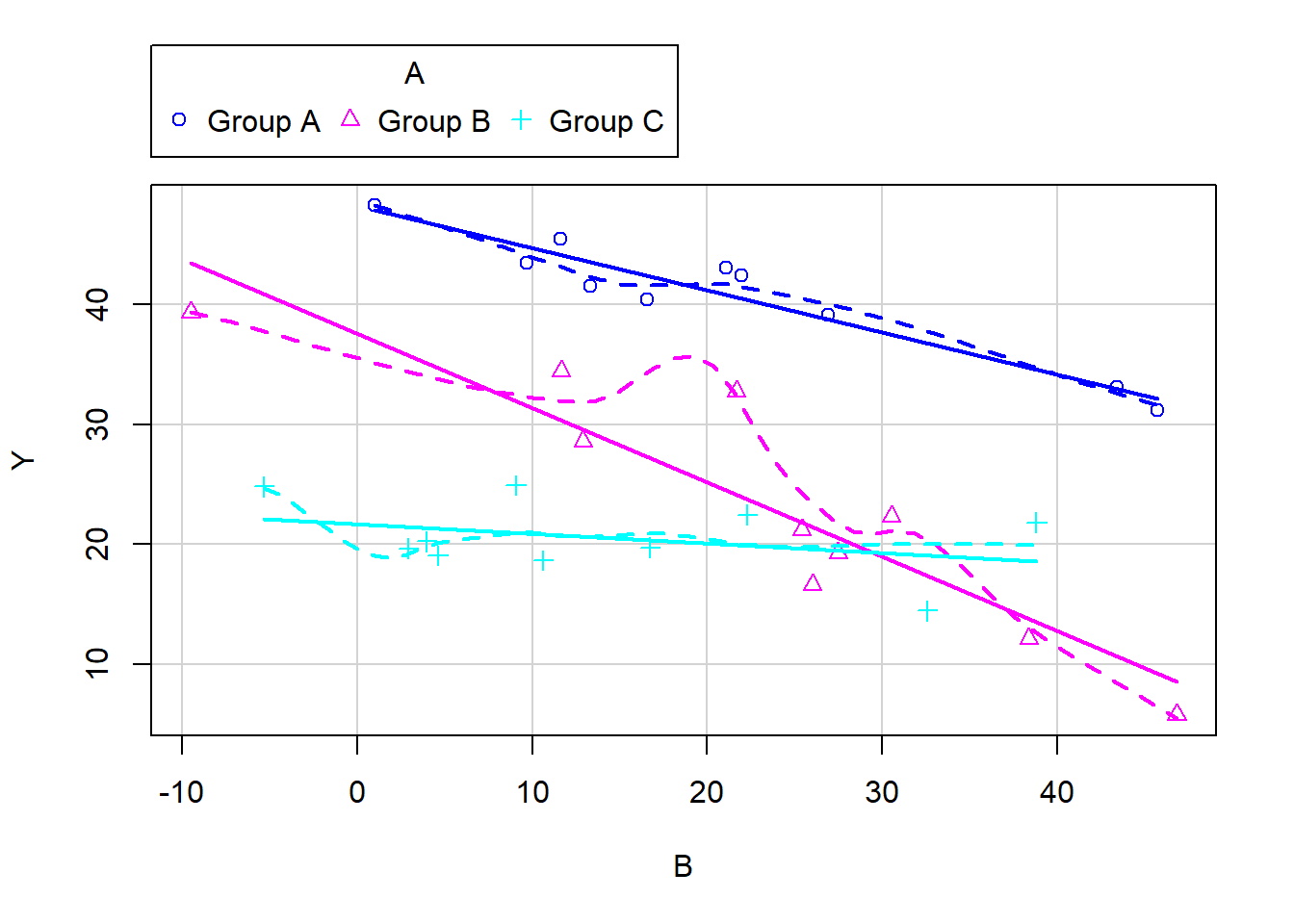
>
> boxplot(Y ~ A, data1)
>
> # OR via ggplot
> ggplot(data1, aes(y = Y, x = B, group = A)) + geom_point() + geom_smooth(method = "lm")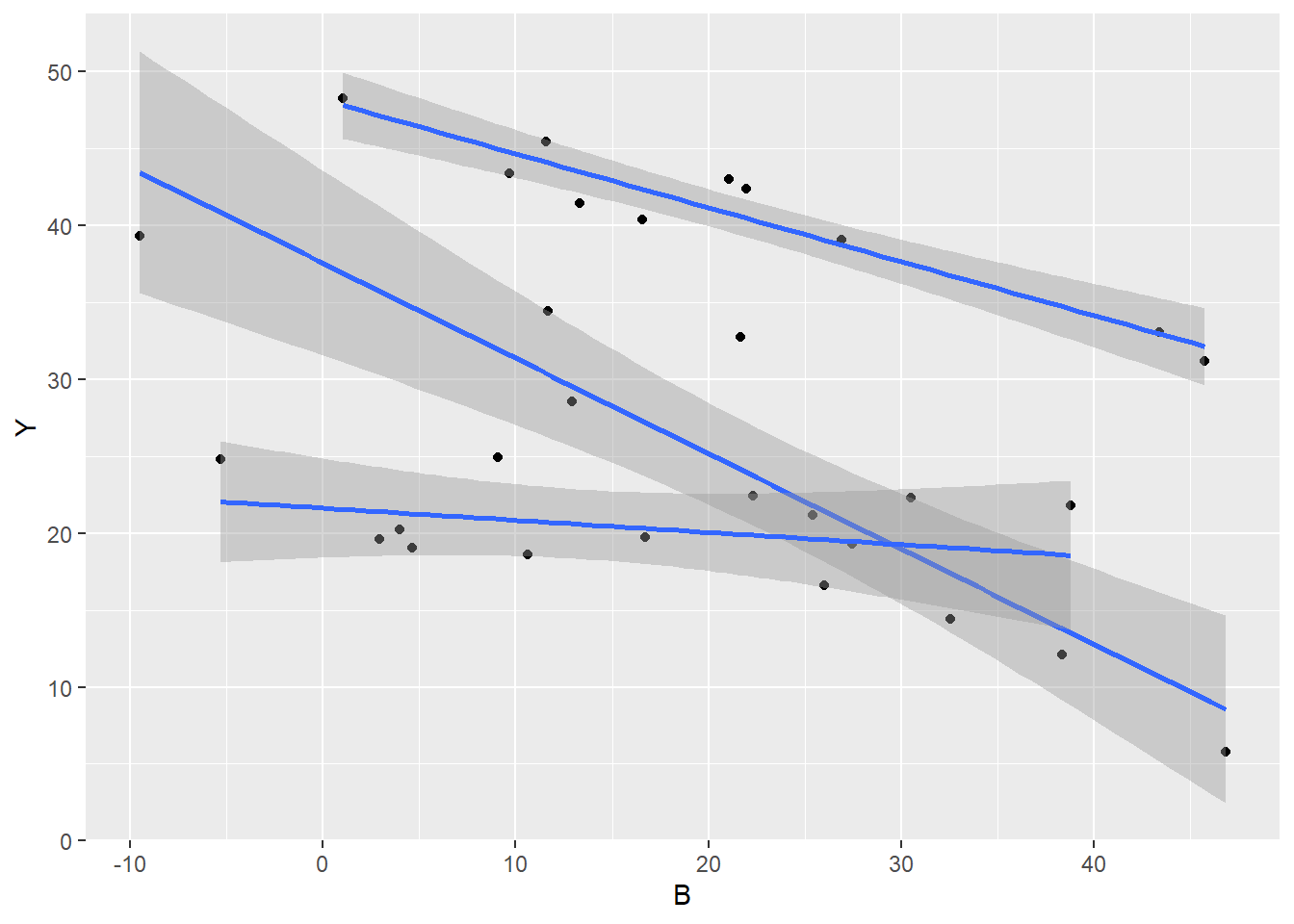
>
> ggplot(data1, aes(y = Y, x = A)) + geom_boxplot()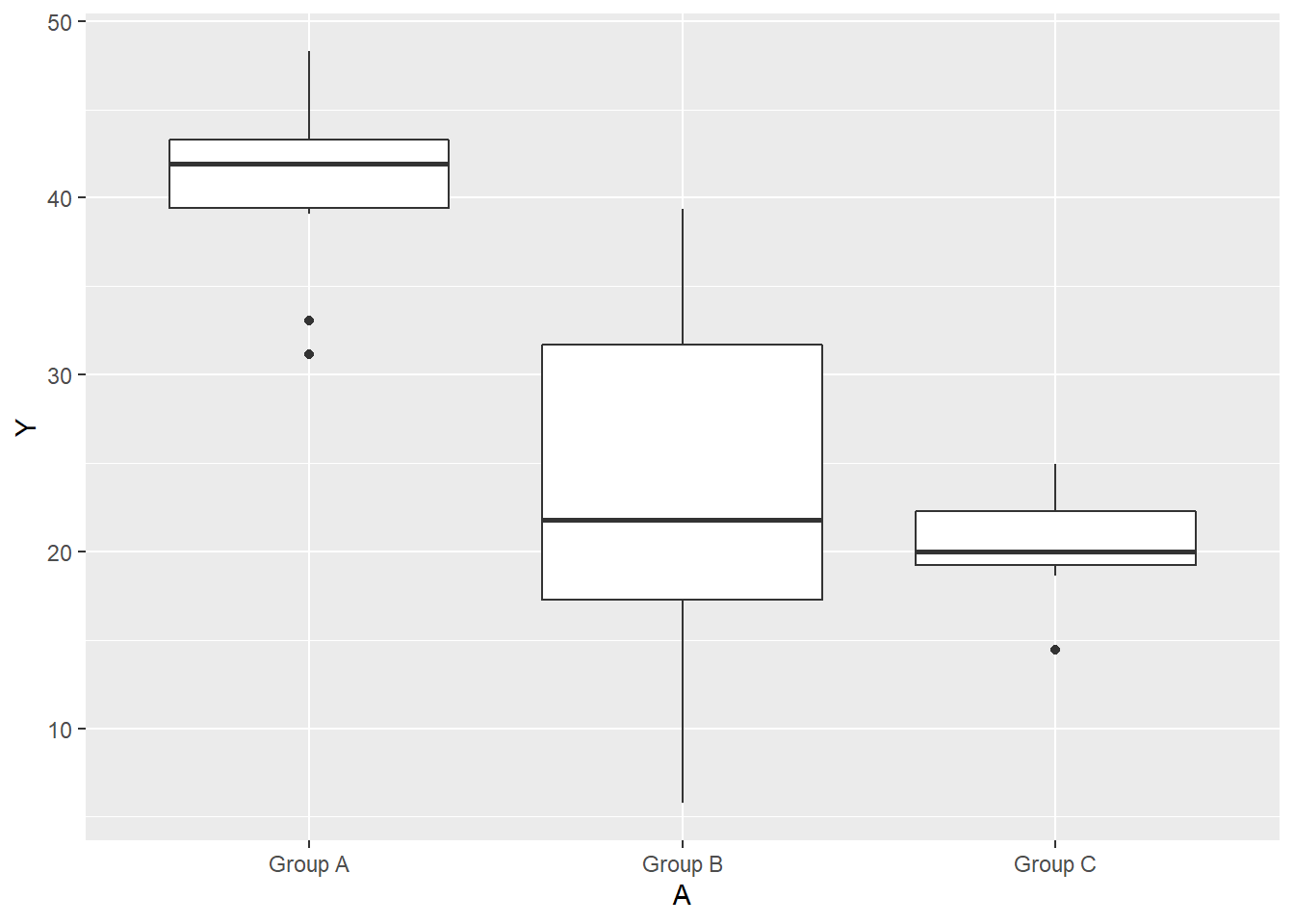
The slopes (\(Y\) vs B trends) do appear to differ between treatment groups - in particular, Group C seems to portray a different trend to Groups A and B.
> anova(lm(Y ~ B * A, data = data1))
Analysis of Variance Table
Response: Y
Df Sum Sq Mean Sq F value Pr(>F)
B 1 442.02 442.02 41.380 1.187e-06 ***
A 2 2760.60 1380.30 129.217 1.418e-13 ***
B:A 2 285.75 142.87 13.375 0.0001251 ***
Residuals 24 256.37 10.68
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1There is strong evidence to suggest that the assumption of equal slopes is violated.
Fitting the model
> modelString2 = "
+ data {
+ int<lower=1> n;
+ int<lower=1> nX;
+ vector [n] y;
+ matrix [n,nX] X;
+ }
+ parameters {
+ vector[nX] beta;
+ real<lower=0> sigma;
+ }
+ transformed parameters {
+ vector[n] mu;
+
+ mu = X*beta;
+ }
+ model {
+ // Likelihood
+ y~normal(mu,sigma);
+
+ // Priors
+ beta ~ normal(0,100);
+ sigma~cauchy(0,5);
+ }
+ generated quantities {
+ vector[n] log_lik;
+
+ for (i in 1:n) {
+ log_lik[i] = normal_lpdf(y[i] | mu[i], sigma);
+ }
+ }
+
+ "
>
> ## write the model to a text file
> writeLines(modelString2, con = "ancovaModel2.stan")Arrange the data as a list (as required by Stan). As input, Stan will need to be supplied with: the response variable, the predictor matrix, the number of predictors, the total number of observed items. This all needs to be contained within a list object. We will create two data lists, one for each of the hypotheses.
> Xmat <- model.matrix(~A * B, data1)
> data1.list <- with(data1, list(y = Y, X = Xmat, nX = ncol(Xmat), n = nrow(data1)))Define the nodes (parameters and derivatives) to monitor and the chain parameters.
> params <- c("beta", "sigma", "log_lik")
> nChains = 2
> burnInSteps = 500
> thinSteps = 1
> numSavedSteps = 2000 #across all chains
> nIter = ceiling(burnInSteps + (numSavedSteps * thinSteps)/nChains)
> nIter
[1] 1500Start the JAGS model (check the model, load data into the model, specify the number of chains and compile the model).
> data1.rstan <- stan(data = data1.list, file = "ancovaModel2.stan", chains = nChains, pars = params,
+ iter = nIter, warmup = burnInSteps, thin = thinSteps)
SAMPLING FOR MODEL 'ancovaModel2' NOW (CHAIN 1).
Chain 1:
Chain 1: Gradient evaluation took 0 seconds
Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Chain 1: Adjust your expectations accordingly!
Chain 1:
Chain 1:
Chain 1: Iteration: 1 / 1500 [ 0%] (Warmup)
Chain 1: Iteration: 150 / 1500 [ 10%] (Warmup)
Chain 1: Iteration: 300 / 1500 [ 20%] (Warmup)
Chain 1: Iteration: 450 / 1500 [ 30%] (Warmup)
Chain 1: Iteration: 501 / 1500 [ 33%] (Sampling)
Chain 1: Iteration: 650 / 1500 [ 43%] (Sampling)
Chain 1: Iteration: 800 / 1500 [ 53%] (Sampling)
Chain 1: Iteration: 950 / 1500 [ 63%] (Sampling)
Chain 1: Iteration: 1100 / 1500 [ 73%] (Sampling)
Chain 1: Iteration: 1250 / 1500 [ 83%] (Sampling)
Chain 1: Iteration: 1400 / 1500 [ 93%] (Sampling)
Chain 1: Iteration: 1500 / 1500 [100%] (Sampling)
Chain 1:
Chain 1: Elapsed Time: 0.117 seconds (Warm-up)
Chain 1: 0.088 seconds (Sampling)
Chain 1: 0.205 seconds (Total)
Chain 1:
SAMPLING FOR MODEL 'ancovaModel2' NOW (CHAIN 2).
Chain 2:
Chain 2: Gradient evaluation took 0 seconds
Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Chain 2: Adjust your expectations accordingly!
Chain 2:
Chain 2:
Chain 2: Iteration: 1 / 1500 [ 0%] (Warmup)
Chain 2: Iteration: 150 / 1500 [ 10%] (Warmup)
Chain 2: Iteration: 300 / 1500 [ 20%] (Warmup)
Chain 2: Iteration: 450 / 1500 [ 30%] (Warmup)
Chain 2: Iteration: 501 / 1500 [ 33%] (Sampling)
Chain 2: Iteration: 650 / 1500 [ 43%] (Sampling)
Chain 2: Iteration: 800 / 1500 [ 53%] (Sampling)
Chain 2: Iteration: 950 / 1500 [ 63%] (Sampling)
Chain 2: Iteration: 1100 / 1500 [ 73%] (Sampling)
Chain 2: Iteration: 1250 / 1500 [ 83%] (Sampling)
Chain 2: Iteration: 1400 / 1500 [ 93%] (Sampling)
Chain 2: Iteration: 1500 / 1500 [100%] (Sampling)
Chain 2:
Chain 2: Elapsed Time: 0.135 seconds (Warm-up)
Chain 2: 0.092 seconds (Sampling)
Chain 2: 0.227 seconds (Total)
Chain 2:
>
> print(data1.rstan, par = c("beta", "sigma"))
Inference for Stan model: ancovaModel2.
2 chains, each with iter=1500; warmup=500; thin=1;
post-warmup draws per chain=1000, total post-warmup draws=2000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
beta[1] 48.27 0.10 2.02 44.26 46.91 48.27 49.64 52.11 416 1.01
beta[2] -10.66 0.13 2.88 -16.31 -12.59 -10.59 -8.71 -4.97 456 1.01
beta[3] -26.64 0.12 2.58 -31.78 -28.35 -26.63 -24.88 -21.83 446 1.01
beta[4] -0.36 0.00 0.08 -0.51 -0.41 -0.36 -0.30 -0.19 413 1.01
beta[5] -0.26 0.01 0.11 -0.47 -0.33 -0.26 -0.19 -0.06 448 1.01
beta[6] 0.28 0.01 0.11 0.06 0.20 0.28 0.35 0.51 444 1.01
sigma 3.40 0.02 0.51 2.61 3.03 3.35 3.70 4.55 892 1.00
Samples were drawn using NUTS(diag_e) at Thu Jul 08 21:56:19 2021.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).MCMC diagnostics
> mcmc <- As.mcmc.list(data1.rstan)
>
> denplot(mcmc, parms = c("beta"))
> traplot(mcmc, parms = c("beta"))
Trace plots show no evidence that the chains have not reasonably traversed the entire multidimensional parameter space. When there are a lot of parameters, this can result in a very large number of traceplots. To focus on just certain parameters (such as \(\beta\)s).
> #Raftery diagnostic
> raftery.diag(mcmc)
[[1]]
Quantile (q) = 0.025
Accuracy (r) = +/- 0.005
Probability (s) = 0.95
You need a sample size of at least 3746 with these values of q, r and s
[[2]]
Quantile (q) = 0.025
Accuracy (r) = +/- 0.005
Probability (s) = 0.95
You need a sample size of at least 3746 with these values of q, r and sThe Raftery diagnostics for each chain estimate that we would require no more than \(5000\) samples to reach the specified level of confidence in convergence. As we have \(10500\) samples, we can be confidence that convergence has occurred.
> #Autocorrelation diagnostic
> autocorr.diag(mcmc)
beta[1] beta[2] beta[3] beta[4] beta[5] beta[6]
Lag 0 1.00000000 1.00000000 1.00000000 1.00000000 1.000000000 1.00000000
Lag 1 0.52133621 0.47961518 0.48006368 0.49557839 0.484647725 0.43857462
Lag 5 0.10815621 0.10858977 0.12099743 0.10897400 0.094321819 0.08768325
Lag 10 0.02323635 0.02172072 0.01248018 0.03884082 0.040725525 0.04104549
Lag 50 -0.02517202 -0.01014901 -0.01354615 -0.02683885 0.006803667 -0.03718686
sigma log_lik[1] log_lik[2] log_lik[3] log_lik[4]
Lag 0 1.000000000 1.0000000000 1.00000000 1.000000000 1.000000000
Lag 1 0.330286328 0.3287416125 0.16466773 0.263630939 0.042381030
Lag 5 0.018650146 0.0459147722 0.03357365 0.037871213 0.002576430
Lag 10 0.009958716 -0.0007195014 0.02359746 -0.001944961 0.034040176
Lag 50 -0.017109084 0.0297305579 -0.05000289 -0.021199421 0.003107548
log_lik[5] log_lik[6] log_lik[7] log_lik[8] log_lik[9] log_lik[10]
Lag 0 1.000000000 1.000000000 1.00000000 1.00000000 1.00000000 1.00000000
Lag 1 0.067895542 0.207067870 0.34868581 0.41969611 0.35495723 0.26199421
Lag 5 0.002179134 0.025367313 0.01787823 0.07673962 0.05527256 0.04818544
Lag 10 0.031023818 0.046045000 0.01326053 -0.02276398 0.01043135 0.01795066
Lag 50 0.002360732 -0.006825805 -0.01001529 0.01514547 -0.05348245 -0.05111914
log_lik[11] log_lik[12] log_lik[13] log_lik[14] log_lik[15]
Lag 0 1.000000000 1.000000000 1.000000000 1.00000000 1.0000000000
Lag 1 0.077233436 0.280692350 -0.032864337 0.13957920 0.0331380637
Lag 5 0.017631896 0.004323352 -0.001616507 -0.01277661 0.0191131123
Lag 10 0.004891029 0.022106699 0.008752585 -0.00216129 -0.0002663491
Lag 50 -0.026079786 -0.010567587 -0.013388357 -0.04726101 -0.0662631967
log_lik[16] log_lik[17] log_lik[18] log_lik[19] log_lik[20]
Lag 0 1.0000000000 1.000000000 1.00000000 1.000000000 1.00000000
Lag 1 0.0275584947 0.166954327 0.08222824 -0.034996827 0.21701884
Lag 5 0.0091692084 -0.002111618 0.02186934 -0.002770455 -0.01285682
Lag 10 0.0005335823 0.013162297 0.01010832 -0.021320912 0.02863086
Lag 50 -0.0347631802 -0.017427547 -0.03390931 -0.021089586 -0.01378152
log_lik[21] log_lik[22] log_lik[23] log_lik[24] log_lik[25]
Lag 0 1.000000000 1.000000000 1.000000000 1.000000000 1.000000000
Lag 1 0.174453325 0.288520979 0.054510440 0.002963841 0.028963148
Lag 5 0.011534871 0.018001339 0.005436673 -0.008183169 -0.002581109
Lag 10 -0.011376339 0.028639271 -0.018412521 -0.027595704 -0.014185052
Lag 50 0.007456506 -0.005110738 0.024570249 0.025523622 0.033116119
log_lik[26] log_lik[27] log_lik[28] log_lik[29] log_lik[30]
Lag 0 1.00000000 1.00000000 1.00000000 1.00000000 1.0000000000
Lag 1 0.06665980 -0.03356227 -0.01630716 0.09590753 0.0103297076
Lag 5 0.03629140 -0.03825503 -0.01691709 0.00643628 -0.0057223417
Lag 10 -0.01638445 -0.02604094 -0.01645431 -0.01847180 0.0165542865
Lag 50 -0.01156086 -0.02180248 0.02513814 0.01720924 0.0004258449
lp__
Lag 0 1.000000000
Lag 1 0.533446011
Lag 5 0.086029182
Lag 10 0.008083904
Lag 50 0.038395733> stan_rhat(data1.rstan)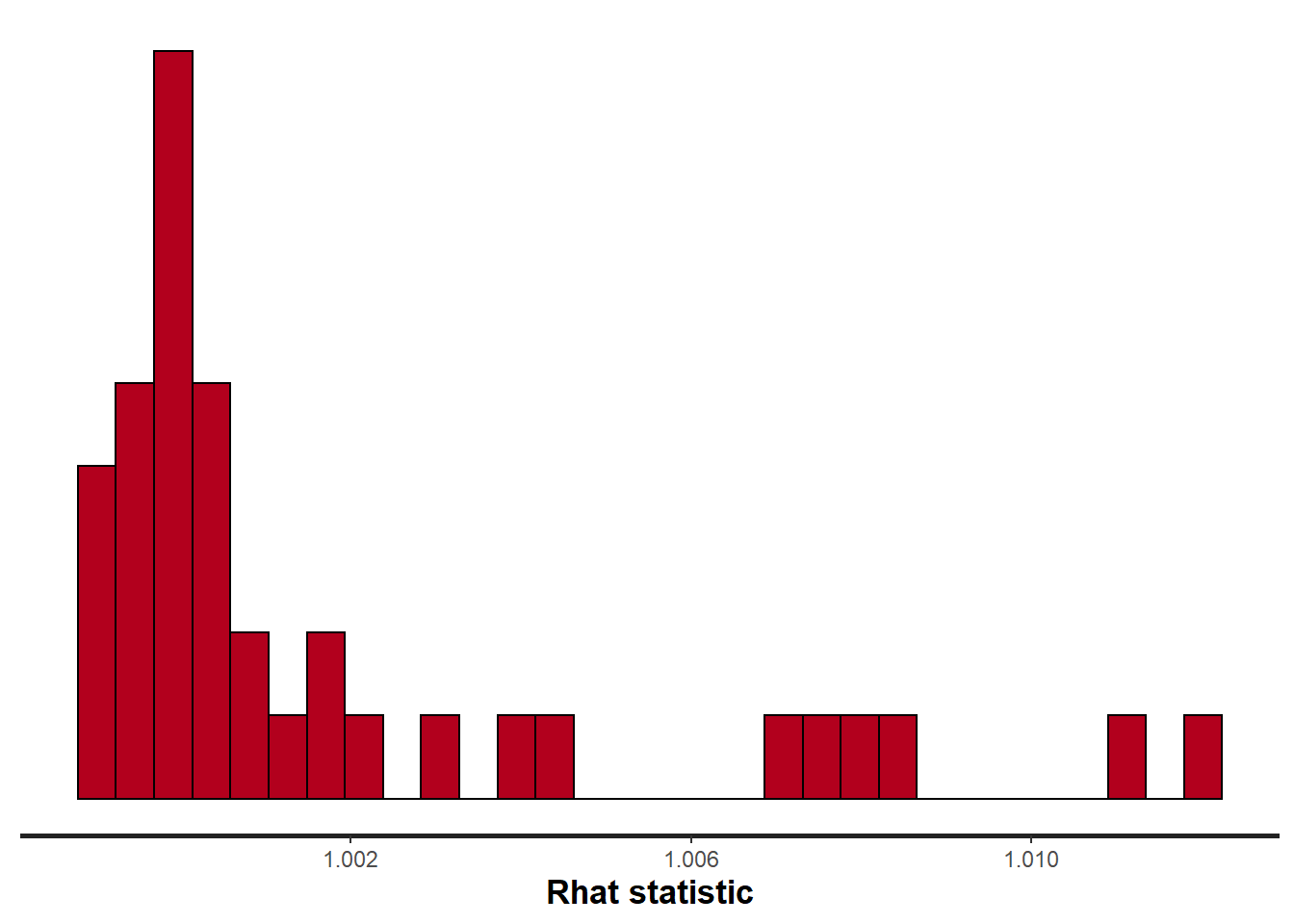
> stan_ess(data1.rstan)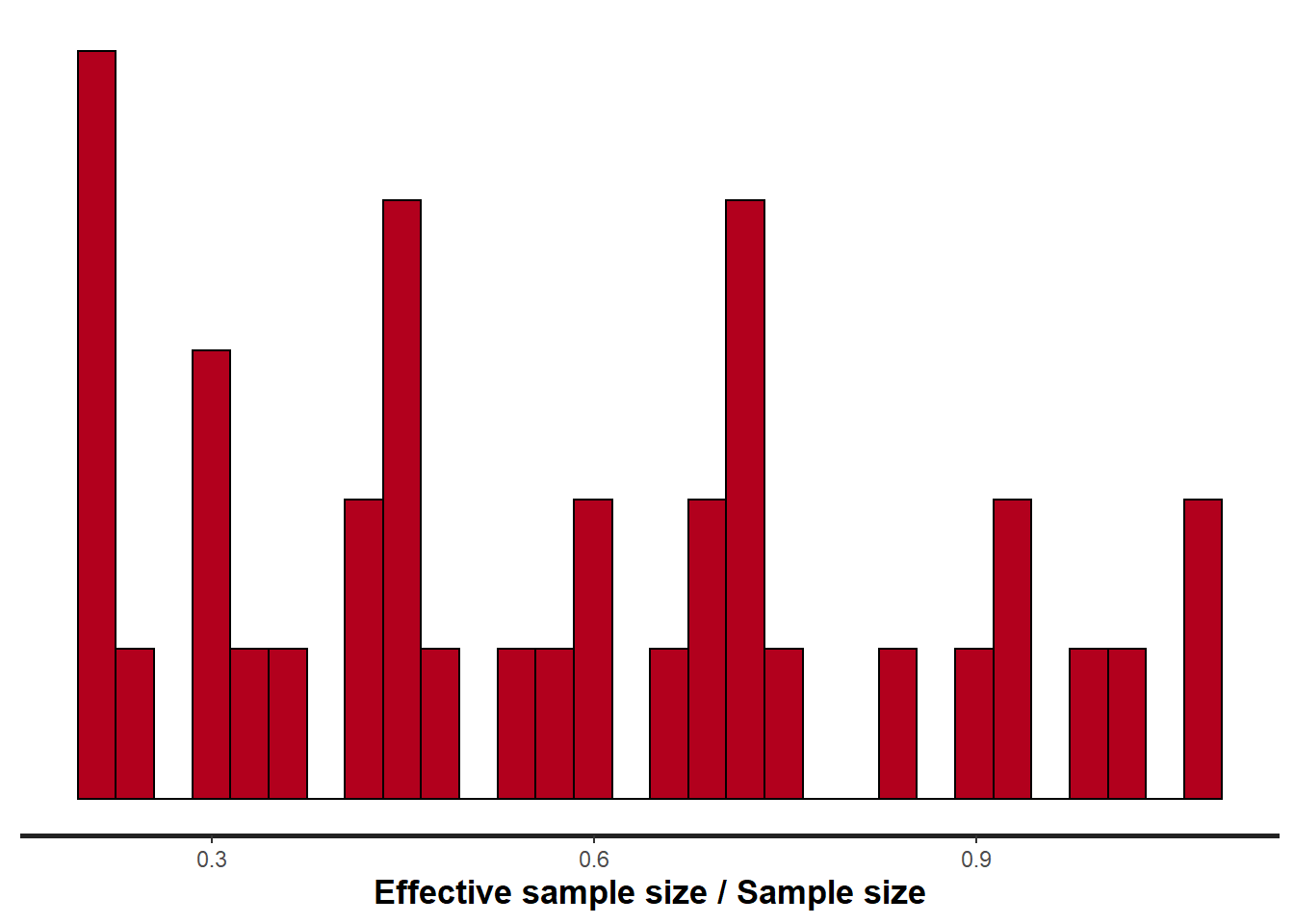
Rhat and effective sample size. In this instance, most of the parameters have reasonably high effective samples and thus there is likely to be a good range of values from which to estimate paramter properties.
Model validation
> mcmc = as.data.frame(data1.rstan) %>% dplyr:::select(contains("beta"),
+ sigma) %>% as.matrix
> # generate a model matrix
> newdata1 = data1
> Xmat = model.matrix(~A * B, newdata1)
> ## get median parameter estimates
> coefs = apply(mcmc[, 1:6], 2, median)
> fit = as.vector(coefs %*% t(Xmat))
> resid = data1$Y - fit
> ggplot() + geom_point(data = NULL, aes(y = resid, x = fit)) + theme_classic()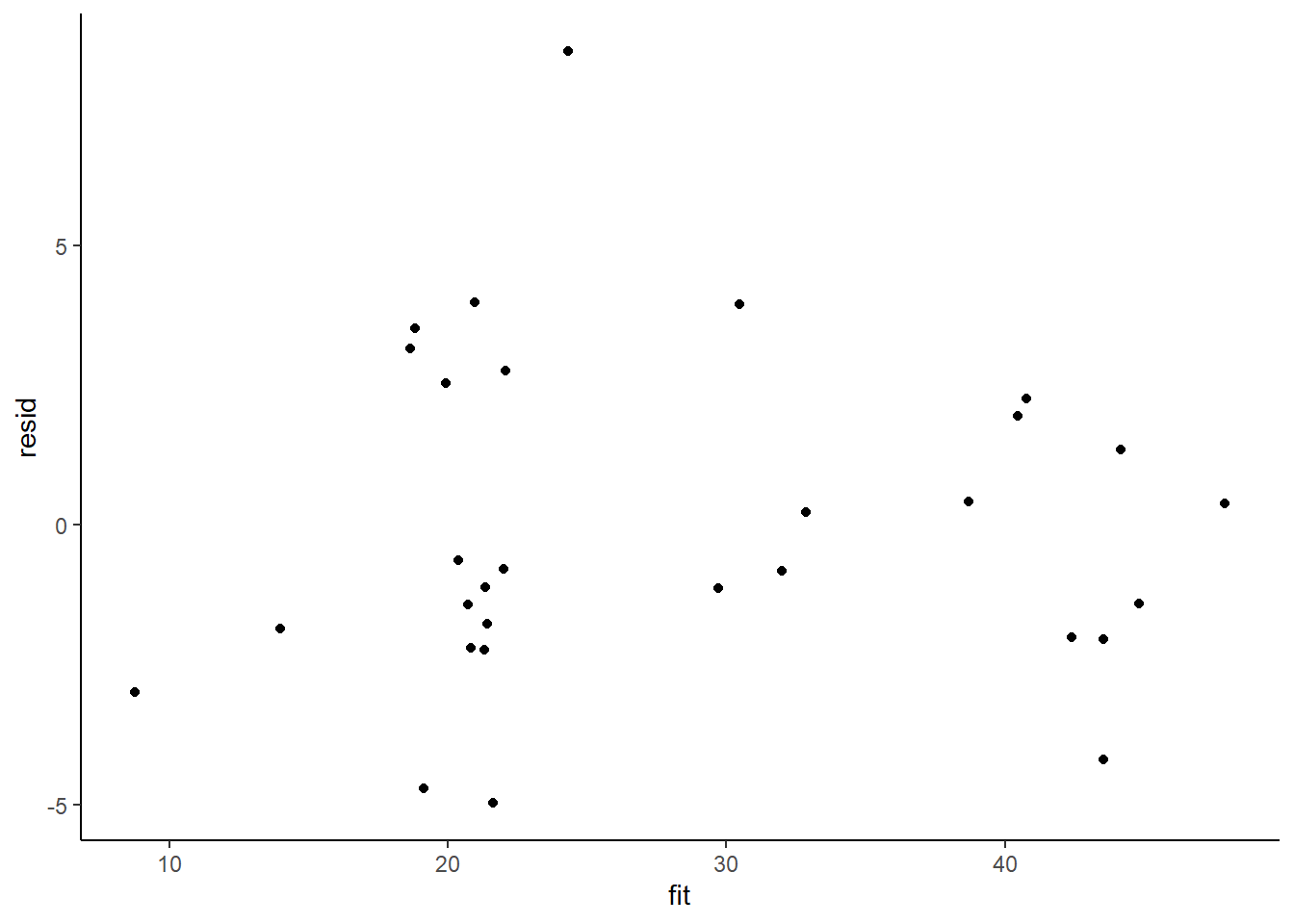
Residuals against predictors
> mcmc = as.data.frame(data1.rstan) %>% dplyr:::select(contains("beta"),
+ sigma) %>% as.matrix
> # generate a model matrix
> newdata1 = newdata1
> Xmat = model.matrix(~A * B, newdata1)
> ## get median parameter estimates
> coefs = apply(mcmc[, 1:6], 2, median)
> fit = as.vector(coefs %*% t(Xmat))
> resid = data1$Y - fit
> newdata1 = newdata1 %>% cbind(fit, resid)
> ggplot(newdata1) + geom_point(aes(y = resid, x = A)) + theme_classic()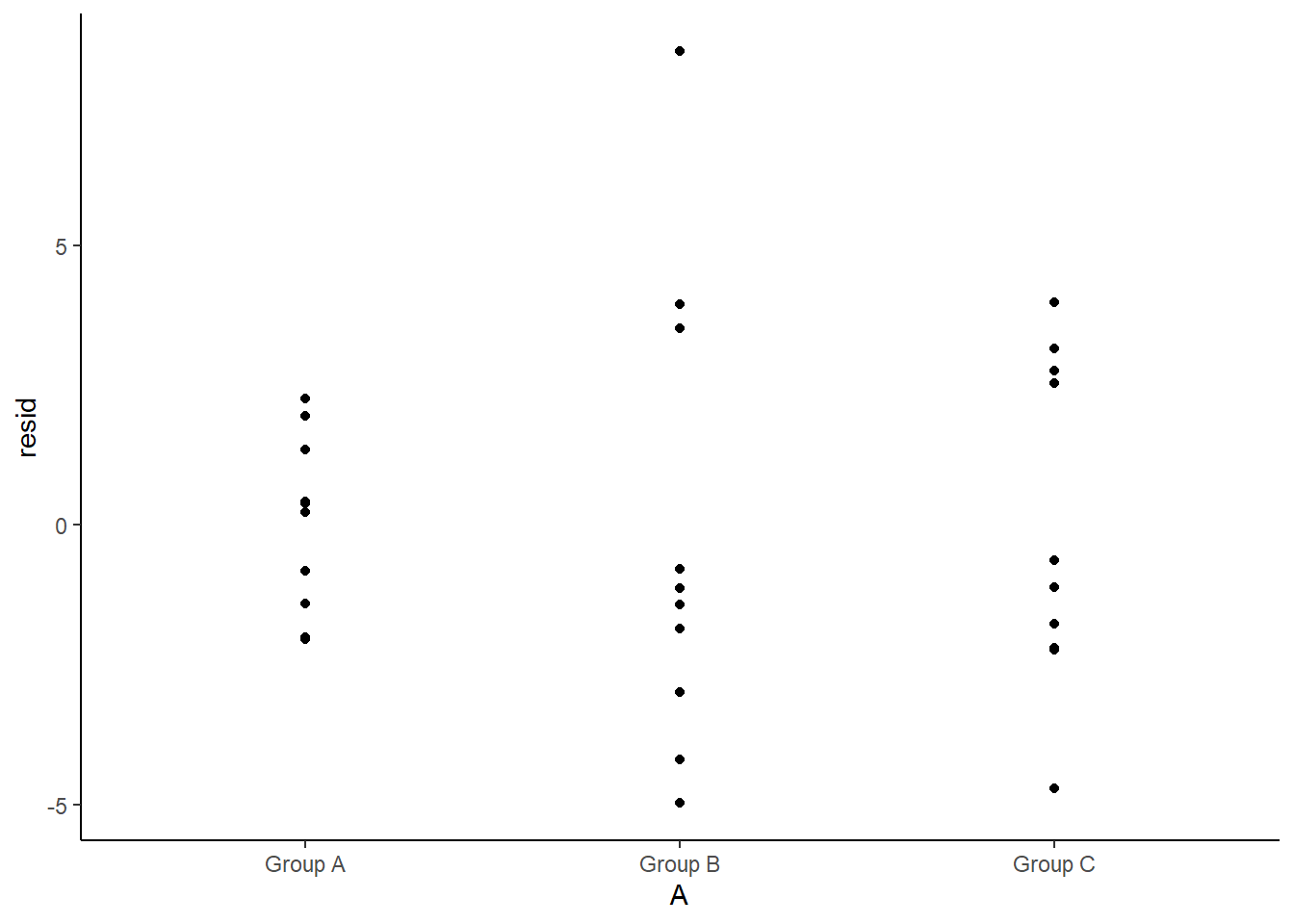
>
> ggplot(newdata1) + geom_point(aes(y = resid, x = B)) + theme_classic()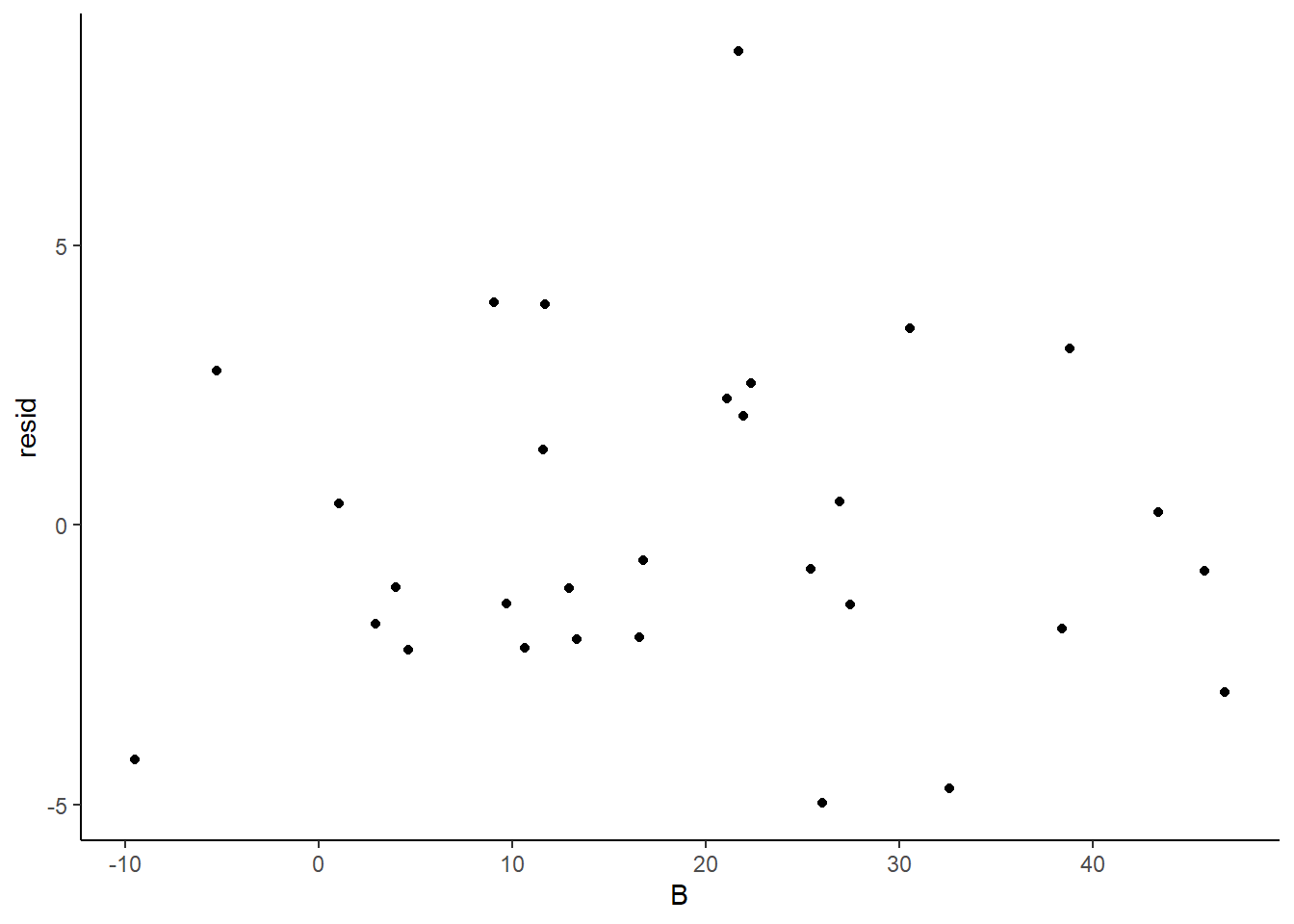
And now for studentised residuals
> mcmc = as.data.frame(data1.rstan) %>% dplyr:::select(contains("beta"),
+ sigma) %>% as.matrix
> # generate a model matrix
> newdata1 = data1
> Xmat = model.matrix(~A * B, newdata1)
> ## get median parameter estimates
> coefs = apply(mcmc[, 1:6], 2, median)
> fit = as.vector(coefs %*% t(Xmat))
> resid = data1$Y - fit
> sresid = resid/sd(resid)
> ggplot() + geom_point(data = NULL, aes(y = sresid, x = fit)) + theme_classic()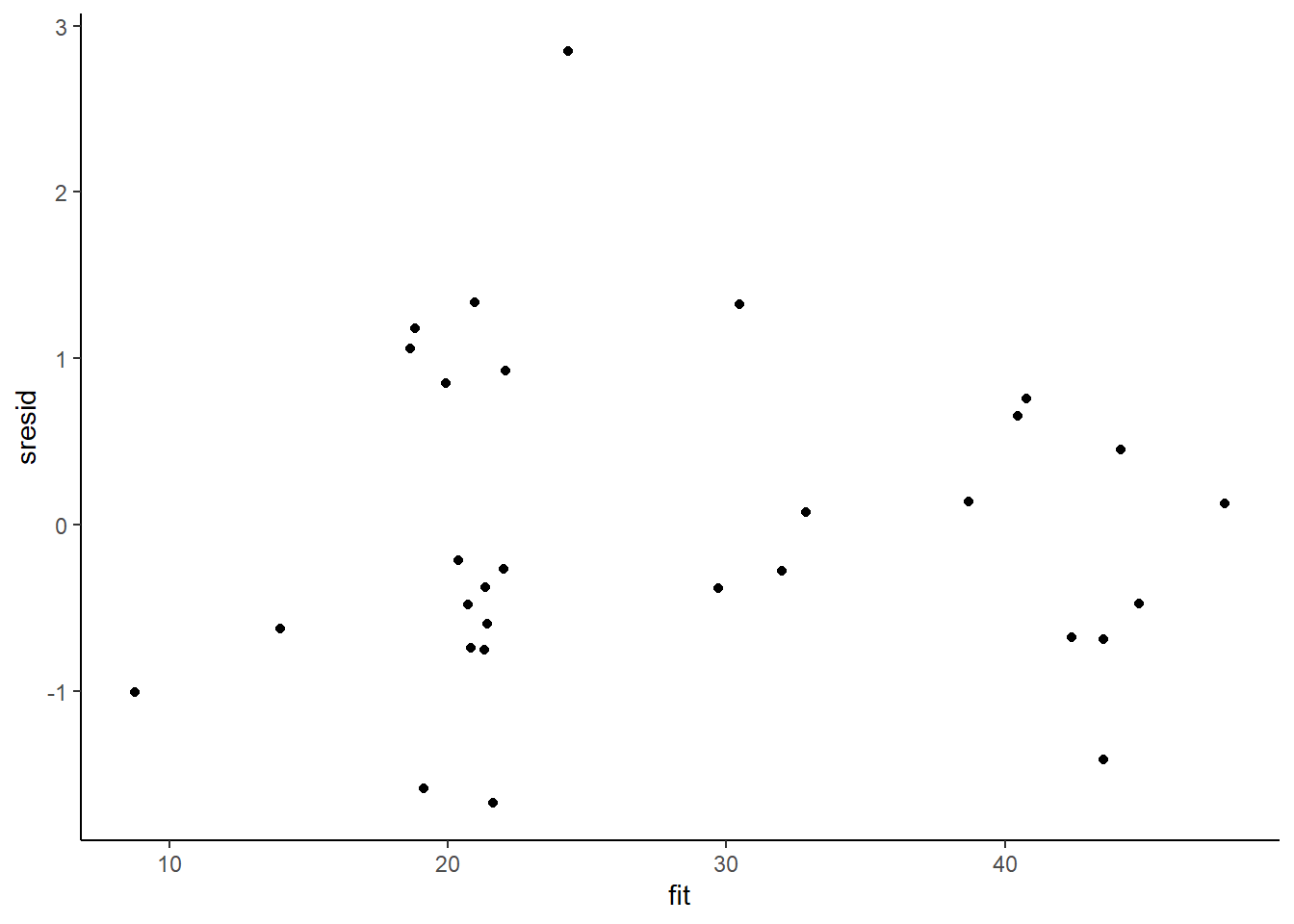
For this simple model, the studentised residuals yield the same pattern as the raw residuals (or the Pearson residuals for that matter). Lets see how well data simulated from the model reflects the raw data.
> mcmc = as.data.frame(data1.rstan) %>% dplyr:::select(contains("beta"),
+ sigma) %>% as.matrix
> # generate a model matrix
> Xmat = model.matrix(~A * B, data1)
> ## get median parameter estimates
> coefs = mcmc[, 1:6]
> fit = coefs %*% t(Xmat)
> ## draw samples from this model
> yRep = sapply(1:nrow(mcmc), function(i) rnorm(nrow(data1), fit[i,
+ ], mcmc[i, "sigma"]))
> newdata1 = data.frame(A = data1$A, B = data1$B, yRep) %>% gather(key = Sample,
+ value = Value, -A, -B)
> ggplot(newdata1) + geom_violin(aes(y = Value, x = A, fill = "Model"),
+ alpha = 0.5) + geom_violin(data = data1, aes(y = Y, x = A,
+ fill = "Obs"), alpha = 0.5) + geom_point(data = data1, aes(y = Y,
+ x = A), position = position_jitter(width = 0.1, height = 0),
+ color = "black") + theme_classic()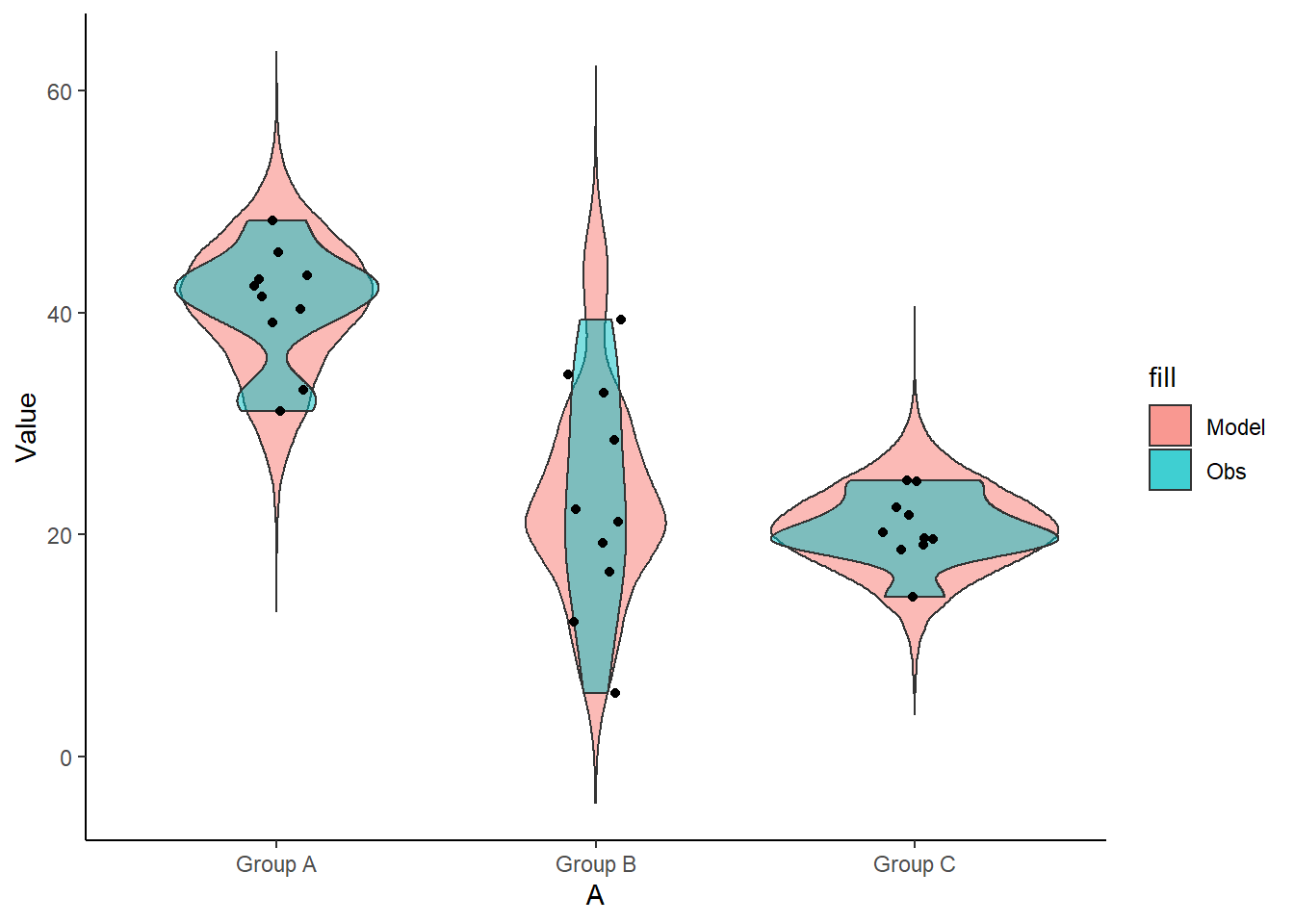
>
> ggplot(newdata1) + geom_violin(aes(y = Value, x = B, fill = "Model",
+ group = B, color = A), alpha = 0.5) + geom_point(data = data1,
+ aes(y = Y, x = B, group = B, color = A)) + theme_classic()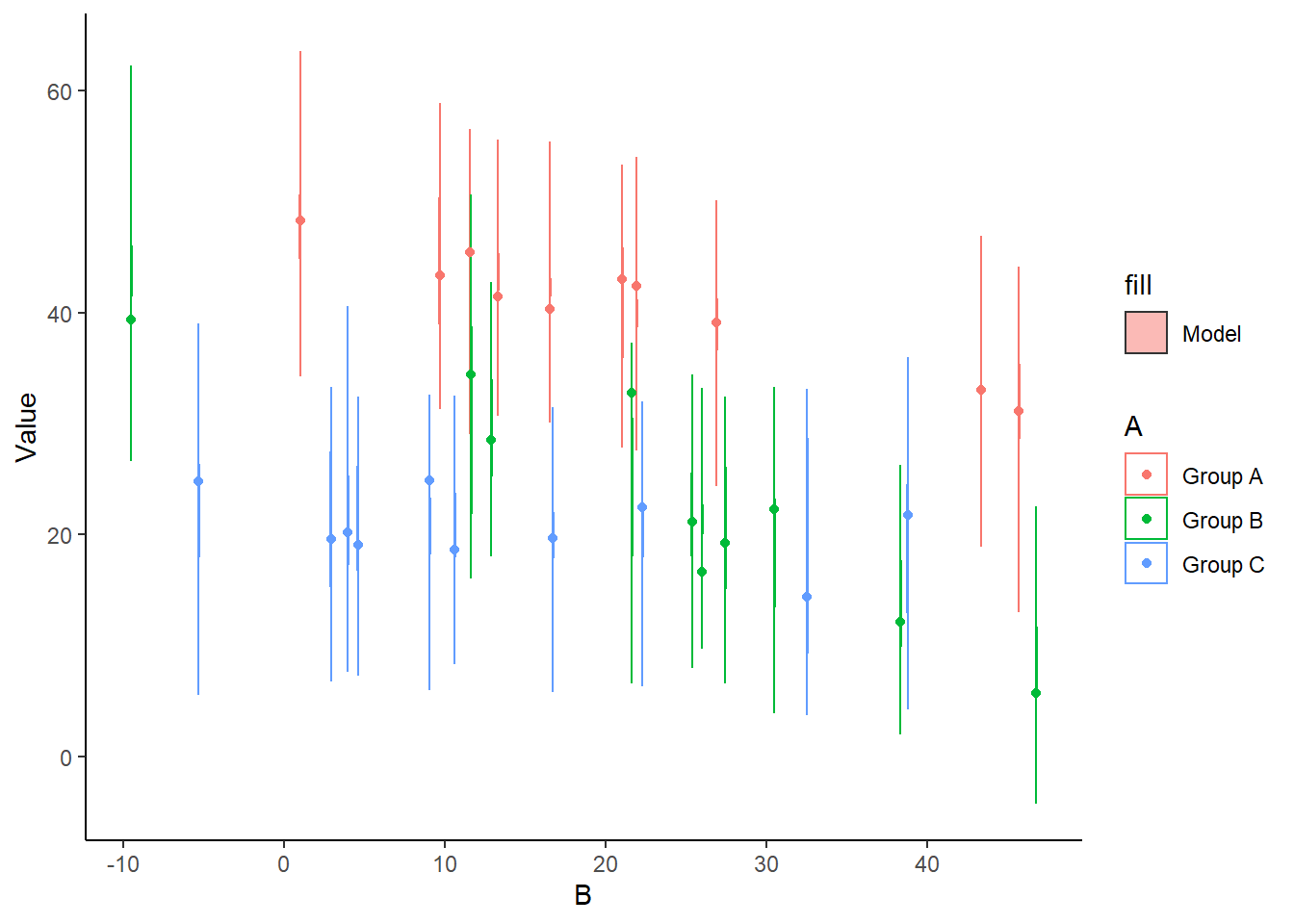
The predicted trends do encapsulate the actual data, suggesting that the model is a reasonable representation of the underlying processes. Note, these are prediction intervals rather than confidence intervals as we are seeking intervals within which we can predict individual observations rather than means. We can also explore the posteriors of each parameter.
> mcmc_intervals(as.matrix(data1.rstan), regex_pars = "beta|sigma")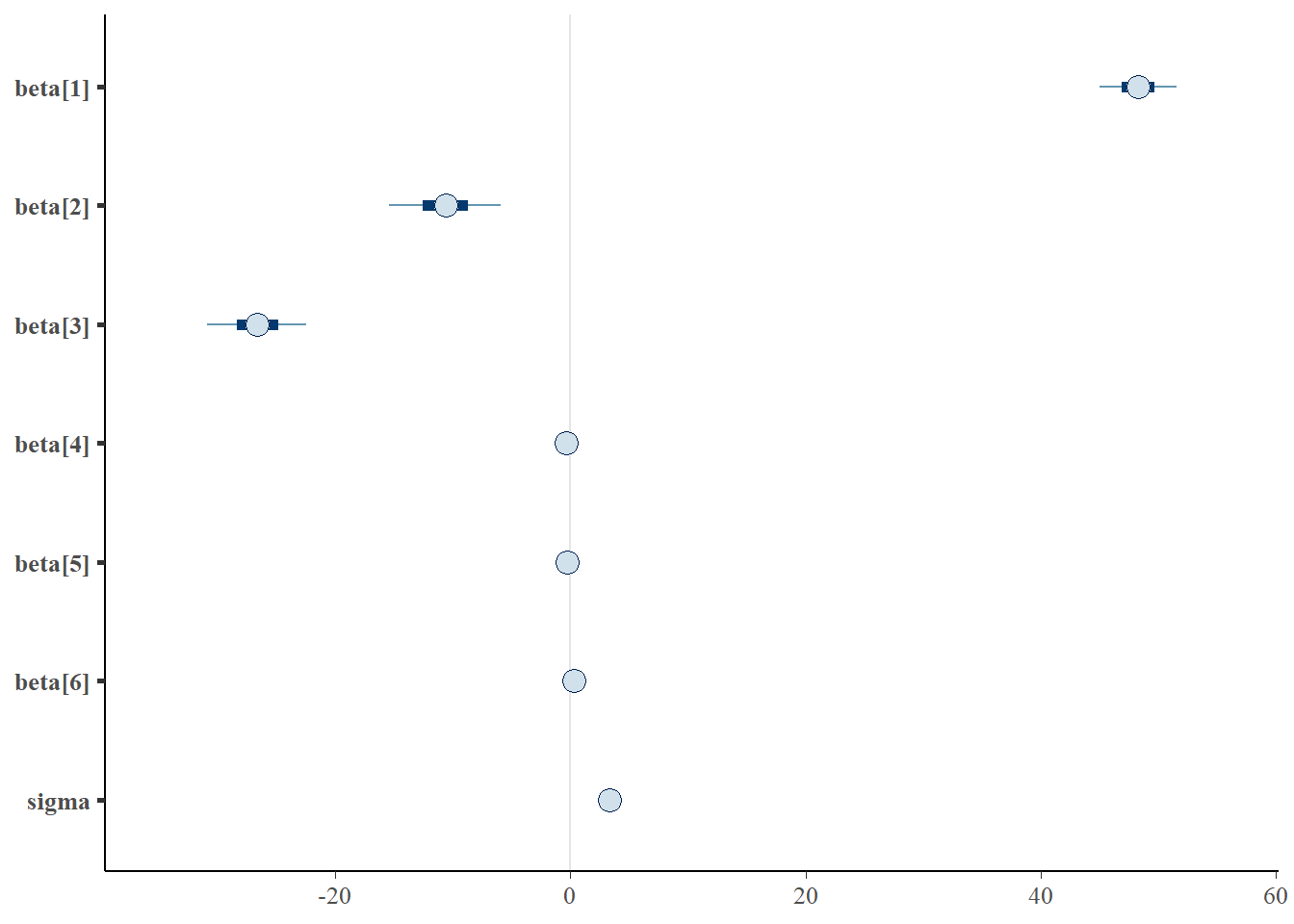
> mcmc_areas(as.matrix(data1.rstan), regex_pars = "beta|sigma")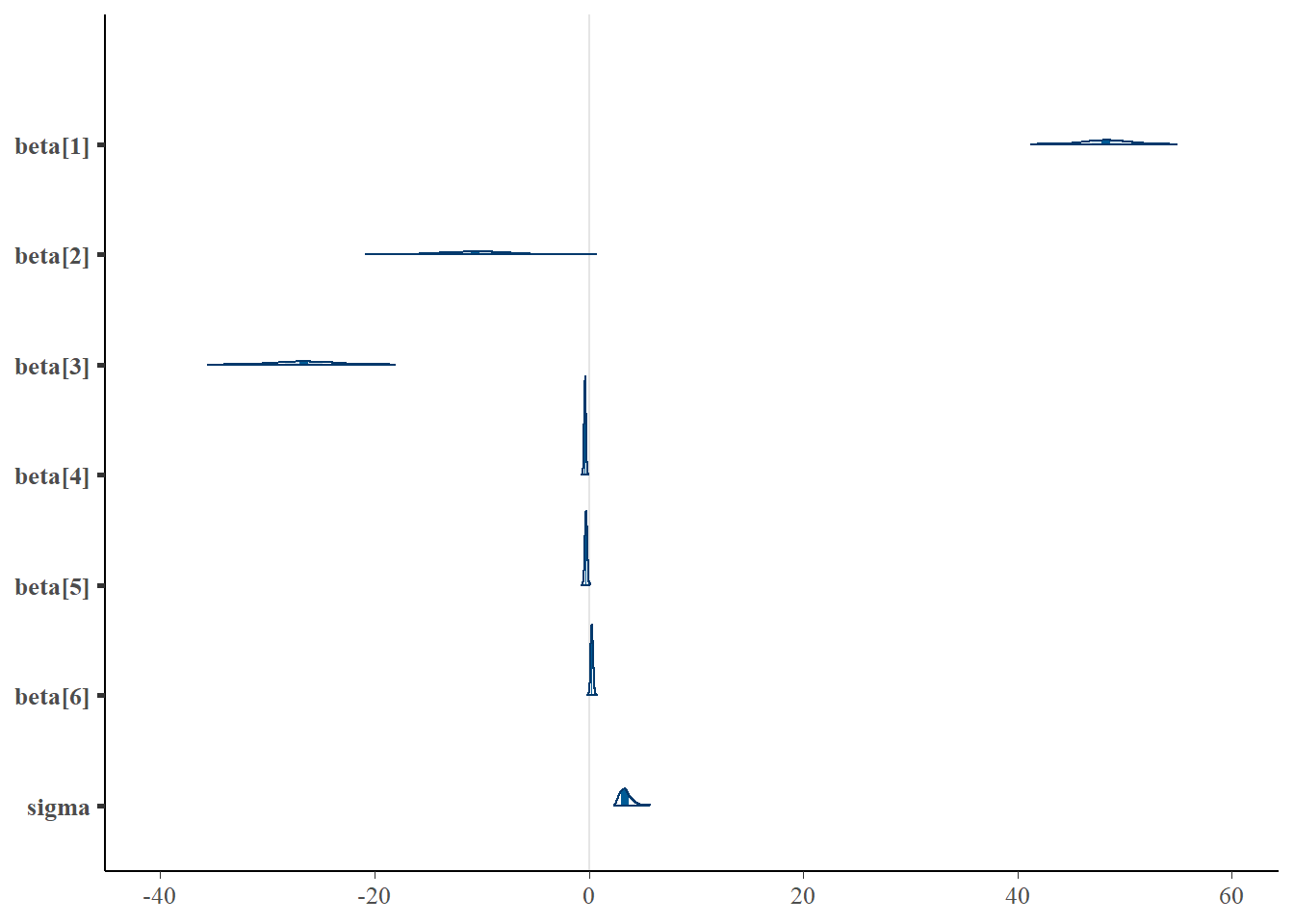
Parameter estimates
First, we look at the results from the additive model.
> print(data1.rstan, pars = c("beta", "sigma"))
Inference for Stan model: ancovaModel2.
2 chains, each with iter=1500; warmup=500; thin=1;
post-warmup draws per chain=1000, total post-warmup draws=2000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
beta[1] 48.27 0.10 2.02 44.26 46.91 48.27 49.64 52.11 416 1.01
beta[2] -10.66 0.13 2.88 -16.31 -12.59 -10.59 -8.71 -4.97 456 1.01
beta[3] -26.64 0.12 2.58 -31.78 -28.35 -26.63 -24.88 -21.83 446 1.01
beta[4] -0.36 0.00 0.08 -0.51 -0.41 -0.36 -0.30 -0.19 413 1.01
beta[5] -0.26 0.01 0.11 -0.47 -0.33 -0.26 -0.19 -0.06 448 1.01
beta[6] 0.28 0.01 0.11 0.06 0.20 0.28 0.35 0.51 444 1.01
sigma 3.40 0.02 0.51 2.61 3.03 3.35 3.70 4.55 892 1.00
Samples were drawn using NUTS(diag_e) at Thu Jul 08 21:56:19 2021.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
>
> # OR
> tidyMCMC(data1.rstan, conf.int = TRUE, conf.method = "HPDinterval", pars = c("beta", "sigma"))
# A tibble: 7 x 5
term estimate std.error conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl>
1 beta[1] 48.3 2.02 44.3 52.1
2 beta[2] -10.6 2.88 -16.6 -5.48
3 beta[3] -26.6 2.58 -31.8 -21.8
4 beta[4] -0.356 0.0805 -0.504 -0.190
5 beta[5] -0.262 0.108 -0.473 -0.0641
6 beta[6] 0.279 0.115 0.0710 0.521
7 sigma 3.35 0.505 2.55 4.42 Conclusions
The intercept of the first group (Group A) is \(48.2\).
The mean of the second group (Group B) is \(-10.6\) units greater than (A).
The mean of the third group (Group C) is \(-26.5\) units greater than (A).
A one unit increase in B in Group A is associated with a \(-0.351\) units increase in \(Y\).
difference in slope between Group B and Group A \(-0.270\).
difference in slope between Group C and Group A \(0.270\).
The \(95\)% confidence interval for the effects of Group B, Group C and the partial slope associated with B do not overlapp with \(0\) implying a significant difference between group A and groups B, C (at the mean level of predictor B) and a significant negative relationship with B (for Group A). The slope associated with Group B was not found to be significantly different from that associated with Group A, however, the slope associated with Group C was found to be significantly less negative than the slope associated with Group A. While workers attempt to become comfortable with a new statistical framework, it is only natural that they like to evaluate and comprehend new structures and output alongside more familiar concepts. One way to facilitate this is via Bayesian p-values that are somewhat analogous to the frequentist p-values for investigating the hypothesis that a parameter is equal to zero.
> ## since values are less than zero
> mcmcpvalue(as.matrix(data1.rstan)[, "beta[2]"]) # effect of (B-A = 0)
[1] 5e-04
> mcmcpvalue(as.matrix(data1.rstan)[, "beta[3]"]) # effect of (C-A = 0)
[1] 0
> mcmcpvalue(as.matrix(data1.rstan)[, "beta[4]"]) # effect of (slope = 0)
[1] 0
> mcmcpvalue(as.matrix(data1.rstan)[, "beta[5]"]) # effect of (slopeB - slopeA = 0)
[1] 0.018
> mcmcpvalue(as.matrix(data1.rstan)[, "beta[6]"]) # effect of (slopeC - slopeA = 0)
[1] 0.0185
> mcmcpvalue(as.matrix(data1.rstan)[, 2:6]) # effect of (model)
[1] 0There is evidence that the reponse differs between the groups.
> (full = loo(extract_log_lik(data1.rstan)))
Computed from 2000 by 30 log-likelihood matrix
Estimate SE
elpd_loo -83.7 4.8
p_loo 7.4 2.2
looic 167.3 9.6
------
Monte Carlo SE of elpd_loo is NA.
Pareto k diagnostic values:
Count Pct. Min. n_eff
(-Inf, 0.5] (good) 27 90.0% 244
(0.5, 0.7] (ok) 1 3.3% 339
(0.7, 1] (bad) 1 3.3% 165
(1, Inf) (very bad) 1 3.3% 15
See help('pareto-k-diagnostic') for details.
>
> # now fit a model without main factor
> modelString3 = "
+ data {
+ int<lower=1> n;
+ int<lower=1> nX;
+ vector [n] y;
+ matrix [n,nX] X;
+ }
+ parameters {
+ vector[nX] beta;
+ real<lower=0> sigma;
+ }
+ transformed parameters {
+ vector[n] mu;
+
+ mu = X*beta;
+ }
+ model {
+ // Likelihood
+ y~normal(mu,sigma);
+
+ // Priors
+ beta ~ normal(0,1000);
+ sigma~cauchy(0,5);
+ }
+ generated quantities {
+ vector[n] log_lik;
+
+ for (i in 1:n) {
+ log_lik[i] = normal_lpdf(y[i] | mu[i], sigma);
+ }
+ }
+
+ "
>
> ## write the model to a stan file
> writeLines(modelString3, con = "ancovaModel3.stan")
>
> Xmat <- model.matrix(~A + B, data1)
> data1.list <- with(data1, list(y = Y, X = Xmat, n = nrow(data1), nX = ncol(Xmat)))
> data1.rstan.red <- stan(data = data1.list, file = "ancovaModel3.stan", chains = nChains,
+ iter = nIter, warmup = burnInSteps, thin = thinSteps)
SAMPLING FOR MODEL 'ancovaModel2' NOW (CHAIN 1).
Chain 1:
Chain 1: Gradient evaluation took 0 seconds
Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Chain 1: Adjust your expectations accordingly!
Chain 1:
Chain 1:
Chain 1: Iteration: 1 / 1500 [ 0%] (Warmup)
Chain 1: Iteration: 150 / 1500 [ 10%] (Warmup)
Chain 1: Iteration: 300 / 1500 [ 20%] (Warmup)
Chain 1: Iteration: 450 / 1500 [ 30%] (Warmup)
Chain 1: Iteration: 501 / 1500 [ 33%] (Sampling)
Chain 1: Iteration: 650 / 1500 [ 43%] (Sampling)
Chain 1: Iteration: 800 / 1500 [ 53%] (Sampling)
Chain 1: Iteration: 950 / 1500 [ 63%] (Sampling)
Chain 1: Iteration: 1100 / 1500 [ 73%] (Sampling)
Chain 1: Iteration: 1250 / 1500 [ 83%] (Sampling)
Chain 1: Iteration: 1400 / 1500 [ 93%] (Sampling)
Chain 1: Iteration: 1500 / 1500 [100%] (Sampling)
Chain 1:
Chain 1: Elapsed Time: 0.093 seconds (Warm-up)
Chain 1: 0.083 seconds (Sampling)
Chain 1: 0.176 seconds (Total)
Chain 1:
SAMPLING FOR MODEL 'ancovaModel2' NOW (CHAIN 2).
Chain 2:
Chain 2: Gradient evaluation took 0 seconds
Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Chain 2: Adjust your expectations accordingly!
Chain 2:
Chain 2:
Chain 2: Iteration: 1 / 1500 [ 0%] (Warmup)
Chain 2: Iteration: 150 / 1500 [ 10%] (Warmup)
Chain 2: Iteration: 300 / 1500 [ 20%] (Warmup)
Chain 2: Iteration: 450 / 1500 [ 30%] (Warmup)
Chain 2: Iteration: 501 / 1500 [ 33%] (Sampling)
Chain 2: Iteration: 650 / 1500 [ 43%] (Sampling)
Chain 2: Iteration: 800 / 1500 [ 53%] (Sampling)
Chain 2: Iteration: 950 / 1500 [ 63%] (Sampling)
Chain 2: Iteration: 1100 / 1500 [ 73%] (Sampling)
Chain 2: Iteration: 1250 / 1500 [ 83%] (Sampling)
Chain 2: Iteration: 1400 / 1500 [ 93%] (Sampling)
Chain 2: Iteration: 1500 / 1500 [100%] (Sampling)
Chain 2:
Chain 2: Elapsed Time: 0.084 seconds (Warm-up)
Chain 2: 0.053 seconds (Sampling)
Chain 2: 0.137 seconds (Total)
Chain 2:
>
> (reduced = loo(extract_log_lik(data1.rstan.red)))
Computed from 2000 by 30 log-likelihood matrix
Estimate SE
elpd_loo -92.1 4.8
p_loo 5.5 1.8
looic 184.2 9.6
------
Monte Carlo SE of elpd_loo is NA.
Pareto k diagnostic values:
Count Pct. Min. n_eff
(-Inf, 0.5] (good) 28 93.3% 765
(0.5, 0.7] (ok) 1 3.3% 164
(0.7, 1] (bad) 1 3.3% 78
(1, Inf) (very bad) 0 0.0% <NA>
See help('pareto-k-diagnostic') for details.
>
> par(mfrow = 1:2, mar = c(5, 3.8, 1, 0) + 0.1, las = 3)
> plot(full, label_points = TRUE)
> plot(reduced, label_points = TRUE)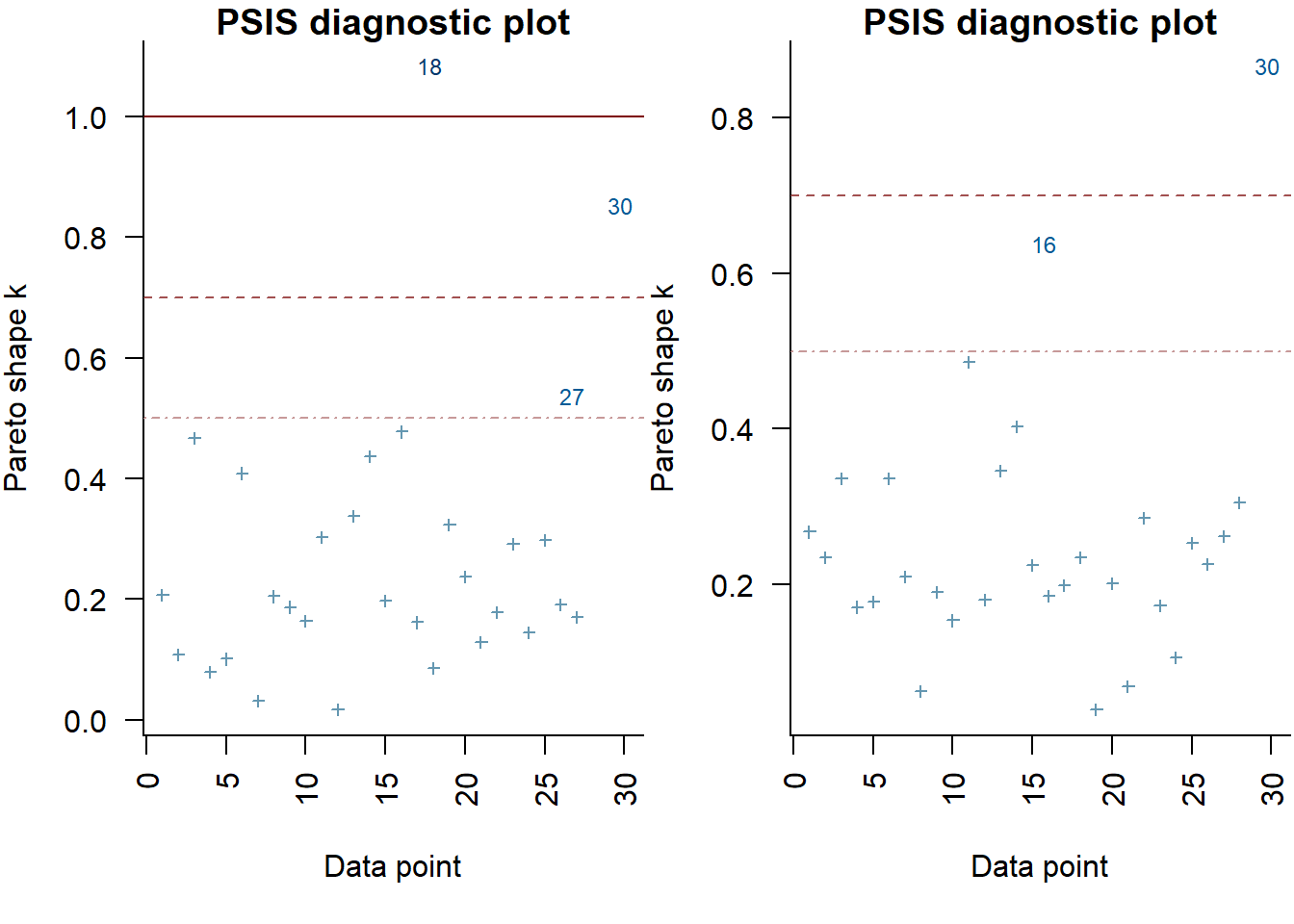
The expected out-of-sample predictive accuracy is substantially lower for the model that includes \(x\). This might be used to suggest that the inferential evidence for a general effect of \(x\) on \(y\).
Graphical summaries
> mcmc = as.matrix(data1.rstan)
> ## Calculate the fitted values
> newdata1 = expand.grid(A = levels(data1$A), B = seq(min(data1$B), max(data1$B),
+ len = 100))
> Xmat = model.matrix(~A * B, newdata1)
> coefs = mcmc[, c("beta[1]", "beta[2]", "beta[3]", "beta[4]", "beta[5]",
+ "beta[6]")]
> fit = coefs %*% t(Xmat)
> newdata1 = newdata1 %>% cbind(tidyMCMC(fit, conf.int = TRUE, conf.method = "HPDinterval"))
>
> ggplot(newdata1, aes(y = estimate, x = B, fill = A)) + geom_ribbon(aes(ymin = conf.low,
+ ymax = conf.high), alpha = 0.2) + geom_line() + scale_y_continuous("Y") +
+ scale_x_continuous("B") + theme_classic()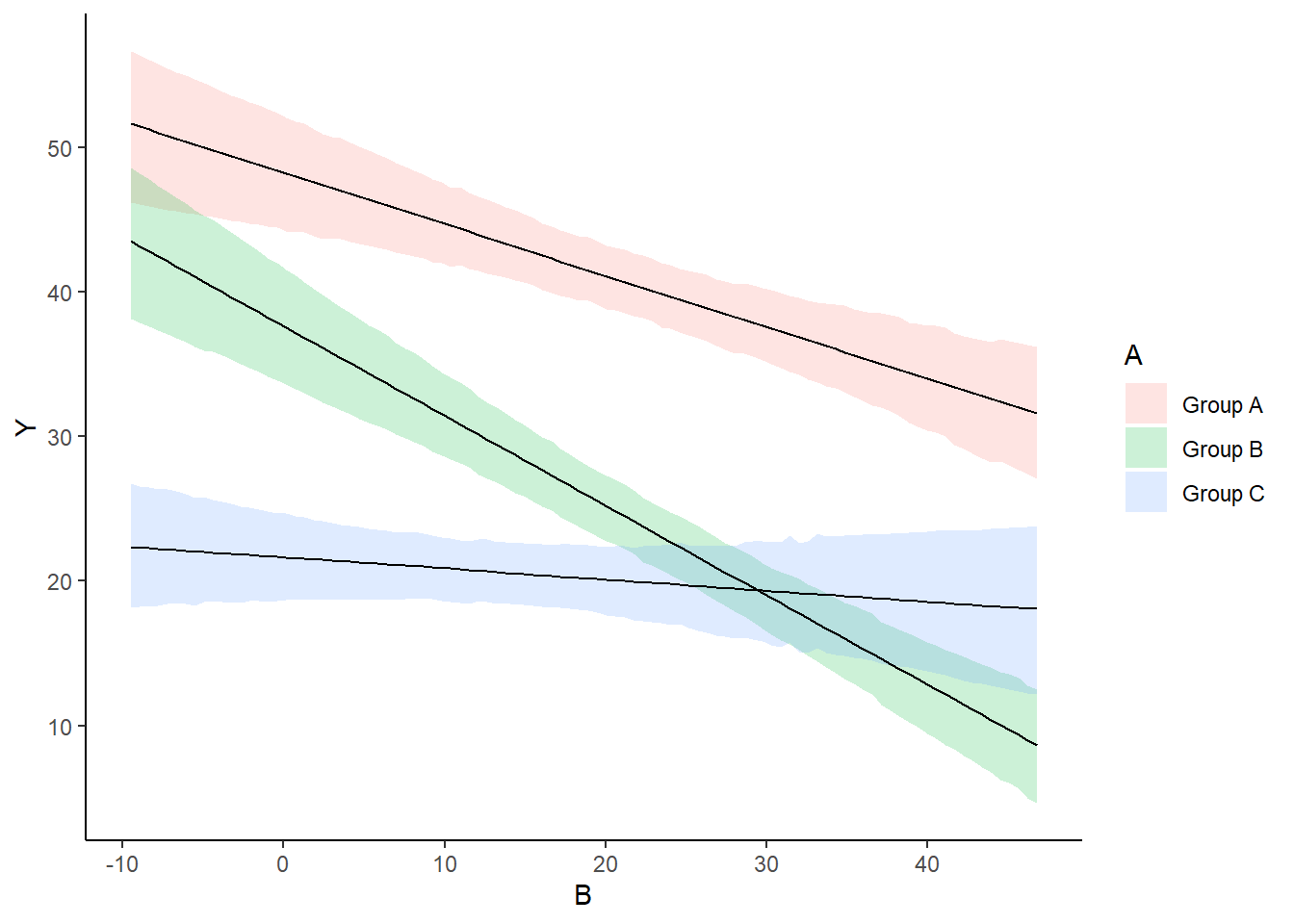
As this is simple single factor ANOVA, we can simple add the raw data to this figure. For more complex designs with additional predictors, it is necessary to plot partial residuals.
> ## Calculate partial residuals fitted values
> fdata1 = rdata1 = data1
> fMat = rMat = model.matrix(~A * B, fdata1)
> fit = as.vector(apply(coefs, 2, median) %*% t(fMat))
> resid = as.vector(data1$Y - apply(coefs, 2, median) %*% t(rMat))
> rdata1 = rdata1 %>% mutate(partial.resid = resid + fit)
>
> ggplot(newdata1, aes(y = estimate, x = B, fill = A)) + geom_point(data = rdata1,
+ aes(y = partial.resid, x = B, color = A)) + geom_ribbon(aes(ymin = conf.low,
+ ymax = conf.high), alpha = 0.2) + geom_line() + scale_y_continuous("Y") +
+ scale_x_continuous("B") + theme_classic()