MissingHE 1.2.1
 Posterior predictive checks
Posterior predictive checksI have finally found some time to update the version for my R package missingHE, for which version 1.2.1 is now available on CRAN. I included two main features to the previous version of the package.
First, I have added a new type of identifying restriction when fitting pattern mixture models through the function “pattern”. Before, only the complete case restriction was available, which identifies the distributions of the missing data with those from the completers. Now the alternative available case restriction is can also be selected, which relies on the distributions that can be identified among the non-completers to identify the distributions of the missing data. In this way, people can choose among at least two options for the type of restrictions and compare how this choice may affect the final estimates.
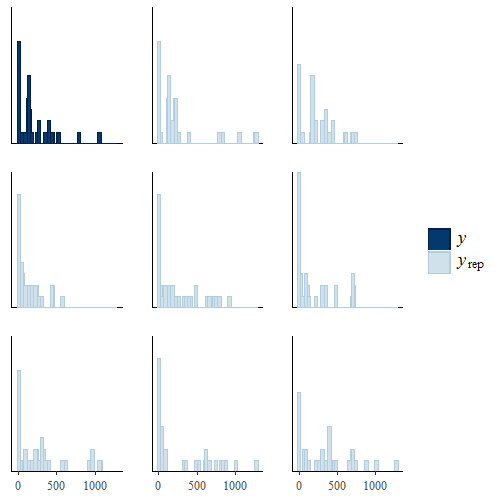
Second, I added a new accessory function called “ppc”, which allows to perform posterior predictive checks using the conditional parameters saved from the fitted model to generate replications of the data at each posterior iteration of the model. The function implements a relatively large number of checks, mostly taken from the R package bayesplot, which allow to assess the fit of the model to the observed data by type of outcome (effects and costs) and treatment group (control and intervention). For example, overalyed density plots can be generated to compare the empirical and replicated densities of the data to detect possible failures of the model.

I feel this is very important as when fitting a Bayesian model it is crucial to assess whether the model seems to adequately capture the different characteristics of the observed data (e.g. skewness, structural values, etc.). A wide range of predictive checks are available, including histograms (see thumbnail pciture), scatterplots, error intervals, empirical cumulative distribution fucntions, statistcis of interest and many others. In addition , these checks can be performed for each type of missingness model and parametric distribution chosen within missingHE.

Of course, it is important to remember that, when dealing with missing data the fit of the model can only be checked with respect to the observed values and therefore this check is only partial since the fit to the unibserved values can never be checked. This is also why it is not meaningful to assess the fit of a model fitted under a missing not at random assumption because this is based on information which is not directly available from the data at hand and thus impossible to check.